

Social Perception of Self-Enhancement Bias and Error
Abstract
Abstract. How do social observers perceive and judge individuals who self-enhance (vs. not)? Using a decision-theoretic framework, we distinguish between self-enhancement bias and error, where the former comprises both correct and incorrect self-perceptions of being better than average. The latter occurs when a claim to be better than others is found to be false. In two studies, we find that when judging people’s competence, observers are sensitive to the accuracy of self-perception. When judging their morality, however, they tend to respond negatively to any claims of being better than average. These findings are further modulated by the domain of performance (intelligence vs. moral aptitude). Implications for the strategic use of self-enhancement claims are discussed.
Leslie Stahl: “You are not known to be a humble man. But I wonder –”
Donald Trump: “I think I am, actually humble. I think I’m much more humble than you would understand.” CBS, Sixty Minutes, July 17, 2016
Self-enhancement is a prominent bias in self-perception. Often, the bias presents itself as the perception of being better than the average person (Alicke & Govorun, 2005). This bias is robust, although there are certain lawful exceptions (Kruger, 1999; Moore & Cain 2007). When people perceive themselves as better than others, an active social comparison may have taken place such that people have lifted their self-perception or lowered their perception of others. Yet, the bias can emerge without active social comparisons. As long as the self is perceived positively and people project their self-perceptions onto others, the logic of statistical regression implies that perceptions of others will be less positive than self-perceptions (Heck & Krueger, 2015; Krueger, Freestone, & MacInnis, 2013).
Questions have been raised about the rationality, the adaptiveness, and the cognitive and motivational underpinnings of self-enhancement (cf., Alicke & Sedikides, 2011). The question of rationality is whether and under which circumstances self-enhancement bias produces systematic errors. The question of adaptiveness is whether the bias will, on balance, produce desirable consequences for the self-enhancer. The question of motivation is whether the bias serves specific goals or whether it can emerge from cognitive processes not designed for the purpose of producing positive self-perception.
In an influential article, Taylor and Brown (1988) suggested that self-enhancement is one among several motivated biases that are both irrational and adaptive. One of the lines of research that has evolved in the wake of the Taylor-and-Brown article asks how people perceive and judge self-enhancing individuals. This research begins with the assumption that if peers or observers regard a self-enhancer positively, they contribute to that person’s social well-being. Conversely, if they regard a self-enhancer negatively, they put the person’s social well-being at risk. The picture that has emerged is mixed, in part because of the way self-enhancement has been conceptualized and measured. Almost all relevant research scales individuals along a single dimension ranging from strong self-enhancement to strong self-effacement. This method, though attractive for correlational analysis, conflates self-enhancement bias with self-enhancement error: not all who claim to be better than average are wrong. In our research, we depart from this measurement practice by using a decision-theoretic approach (cf. Swets, Dawes, & Monahan, 2000), which enables us to distinguish between those who accurately claim to be better than others and those who commit a self-enhancement error by claiming to be better than others when they are not.
The full application of the decision-theoretic approach permits the categorization of target individuals into four distinctive types depending on how they relate to two criterion questions. The first question is whether they show a bias: do they self-enhance or not? The second question is whether their self-perceptions are accurate, which depends on the fit between self-perception and the person actually being better or worse than average. Crossing the two dimensions of self-perception and reality yields four discrete outcomes or types of persons: A Hit (H) is a true positive, a person who thinks he or she is better than average and actually is. A False Alarm (FA) is a person who believes to be better than average but is not, that is, a person who commits a self-enhancement error. A Miss (M), or false negative, is a person who believes to be worse than average but is not. Finally, a Correct Rejection (CR) is a true negative, a person who believes to be worse than average and is. In previous research conducted using this framework, we found that roughly half of our participants showed a self-enhancement bias, while only a minority was in error (Heck & Krueger, 2015).
The conceptual and empirical separability of four types of self-perceivers raises the possibility that social observers are sensitive to these distinctions. We therefore designed two studies to obtain observer judgments of each of the four types of self-perceivers. In addition, we included in one of these studies truncated target persons, that is, targets who were only described by their self-perception (claiming to be better than average or not) or only by their performance (better than average or not). This way, we were able to situate the findings within the context of the existing literature.
Recall that Taylor and Brown (1988) regarded self-enhancement as irrational but adaptive. They found that the social-comparative index of self-enhancement bias (i.e., the better-than-average-effect) predicted desirable personal outcomes, such as high self-esteem, confidence, and social adjustment (see also Taylor, Lerner, Sherman, Sage, & McDowell, 2003). Others have questioned this claim. These researchers found that individuals who perceived themselves more favorably than they were perceived by others tended to be more narcissistic, less well adjusted, and liked less than other individuals (Colvin, Block, & Funder, 1995; John & Robins, 1994; Lafrenière, Sedikides, Van Tongeren, & Davis, 2015; Moore & Small, 2007; Paulhus, 1998; Robins & Beer, 2001; Schroeder-Abé, Rentzsch, Asendorpf, & Penke, 2015; Tenney & Spellman, 2011).1 Studying small groups in the laboratory and in organizations, Anderson, Ames, and Gosling (2008) found that those who (falsely) enhanced their status were both disliked and punished. It is difficult to reconcile the findings of these two research programs because they construe and measure self-enhancement differently. This limitation also holds for the method introduced by Kwan and colleagues, who computed a difference score by subtracting both a person’s judgment of others (social comparison) and judgments of that person made by others (social reality) from that person’s self-judgment (Kwan, John, Kenny, Bond, & Robins, 2004).
An interesting recent research program has been dedicated to tests of the hubris hypothesis, according to which observers dislike individuals who self-enhance explicitly (Hoorens, Pandelaere, Oldersma, & Sedikides, 2012; Van Damme, Hoorens, & Sedikides, 2016, see also Exline & Geyer, 2004). Observers’ negative perceptions appear to stem primarily from the inference that explicit self-enhancers denigrate others, including the observers themselves. To date, however, this research program has been limited to the study of self-enhancement bias; it has not distinguished between accurate and inaccurate self-enhancers.
We introduce the decision-theoretic perspective to the study of perceptions of self-enhancers (and effacers). To illustrate, imagine a person who represents the overall trends seen in the two research traditions. Enzo believes he is smarter than others, rating himself as an 8 out of 10 and others a 5. His peers, however, rate Enzo as a 7. There is both bias (8 > 5) and error (8 > 7). At the same time, Enzo may score high in both self-esteem and narcissism (as the two are positively correlated), thereby confirming both the idea that self-enhancement is good and that it is bad. According to the decision-theoretic approach, Enzo’s profile is akin to that of a False Alarm, that is, it amounts to a self-enhancement error. Three other types of persons are possible, as noted above, and a full examination requires the study of all four types.
For our study of observer judgments, we adopted the prevalent two-dimensional model of social perception. The two dimensions are known by various names, and there are conceptual differences among available theoretical models (Abele, Cuddy, Judd, & Yzerbyt, 2008; Goodwin, Piazza, & Rozin, 2014). We refer to the two dimensions as competence and morality, and use short scales that performed well in past research. In those research studies, the targets of perception were individuals who had chosen either cooperative or prosocial strategies in social dilemmas (Krueger & Acevedo, 2007; Krueger & DiDonato, 2010; Krueger, Massey, & DiDonato, 2008).
In the first study, we presented targets who had ostensibly taken either a test of general intelligence or a test of moral aptitude, and we asked participants to judge each target on the two dimensions. This design permits a test of whether the dimension of interest (competence, morality) matters in its role as input (of target information) or in its role as output (of observer judgments), or whether the two interact. In the second study, we introduced targets about whom only one piece of information was known: either their self-assessment or their performance on an intelligence test. The provision of self-assessment information represents the situation found in the social-comparison paradigm (the target is known to self-enhance or not), whereas the provision of performance information represents the situation found in the social-reality paradigm (the target overestimated him- or herself or not).
We tested two hypotheses with regard to judgments of competence. First, we predicted that observers would judge correct self-enhancers (H) more favorably than incorrect self-enhancers (FA) regardless of the tested domain or the dimension of judgment. Those who accurately claim to perform better than average would be perceived as more competent than those who claim, but fail, to perform better than average. Second, we predicted that observers would judge correct (CR) and incorrect (M) self-effacers similarly. This prediction refers to the joint effects of CR targets being praised for the accuracy of their self-judgment and M targets being viewed favorably because of their above-average test performance. We were rather confident in these predictions for the target person who took an intelligence test and was judged on the dimension of competence because this case involves a match between domain of test and dimension of judgment. The predicted pattern can be described as an interaction between reality (above- or below-average performance) and self-perception (of being above or below average). One may expect a main effect of reality such that those who score above average (Hits [H] and Misses [M]) are rated as more competent than those who do not (False Alarms [FA] and Correct Rejections [CR]). Yet, we may also expect that observers value accuracy (Tenney, Vazire, & Mehl, 2013), and judge those whose self-perception is accurate (H and CR) as more competent than those targets whose self-perception is incorrect (FA and M). The conjunction of these two predictions yields a rank order of competence judgments (H > CR ≈ M > FA) that characterizes a statistical interaction between reality and perception. For a target person who took a morality test, we expect similar judgments of competence. Any successful test performance and accurate self-perception should be credited with high ratings of competence.
The observer’s psychological situation changes when asked to judge a target’s morality. Our third hypothesis was that observers might give a moral credit to self-effacers (CR and M > H and FA), which may simply reflect the dislike of self-enhancers (we address the subtle difference between these two possibilities in Study 2), or the moral praiseworthiness of humility. Consider the target who took an intelligence test. There is no reason to expect a reality effect for morality, that is, to think high scorers are seen as more or less moral than low scorers. One exploratory goal of our study was to see if self-enhancement error (FA) provokes the most negative morality judgments, that is, whether there is also an interactive effect of reality and perception of the kind we hypothesized for judgments of competence. Of special interest are judgments of targets who claim to be more moral than average. This type of self-claim raises a humility paradox. A person may gain moral credit for scoring high on a morality test but lose credit for predicting this result. Conversely, a person may lose credit for scoring low but gain credit for predicting it.
The findings provided by our studies should be instructive for questions of how social impressions can be managed effectively (Leary & Baumeister, 2000; Paulhus, 1984). After reviewing the findings, we therefore close with a discussion of how the reputational effects of self-enhancement may inform a person’s decision to self-enhance.
Study 1: Judging the Four Decision-Theoretic Types
Respondents received brief descriptions of hypothetical individuals who had taken either a test of general intelligence or a test of moral aptitude. All participants were presented with descriptions of four target individuals representing a full crossing of claiming to have scored better than average (or not) and actually having scored better than average (or not). Hence, the study design had one between-participants variable (type of test taken by the target) and two within-participant variables (perception and reality of the target person’s self-prediction). Respondents rated each target person on a series of trait adjectives used in previous research of this type (e.g., Krueger & Acevedo, 2007) to capture the two prominent dimensions of social judgment, competence and morality (Abele et al., 2008).2
Method
Participants (N = 200) were recruited on Amazon Mechanical Turk (MTurk; Amazon, 2014). All participants were screened using TurkGate to ensure that they had not previously participated in our studies (Goldin & Darlow, 2013). Participants received $0.30 as compensation. Average completion time was 3:41 min. The data of two participants, who selected the scale midpoint for each rating, were excluded. Gender and age information was not collected.
Sample size (with n = 99 for each of the between-respondents conditions) was set so that small to medium effects could be detected with an acceptable probability. Estimates obtained with G*Power (Faul, Erdfelder, Lang, & Buchner, 2007) suggested that within-respondent tests of reasonable mean differences of d = .28 and .33 would, respectively, be statistically significant with a probability of .80 or .90.
Procedures and Design
Survey materials were presented online (Qualtrics, 2013) to be accessible for residents of the United States. All participants provided informed consent and were told that they would read about four target individuals who had completed a test of intelligence and who estimated their own performance on that test before knowing the actual result. The test was either one of “general intelligence” or “moral intelligence.” No further information was provided about the nature of these tests. The descriptions merely stated that “those who score high on general (moral) intelligence are thought to have a very high IQ (be very moral people).”
The four target persons were characterized as follows: One target had performed above average and perceived himself as above average. This is the condition of high reality and high perception, or a “Hit” [H]. Another target had performed below average but had perceived himself as better than average (low reality, high perception, or “False Alarm” [FA]). A third had performed above average but perceived himself as worse than average (high reality, low perception, or a “Miss” [M]). Finally, one target had both performed and perceived himself as being below average (low reality, low perception, or “Correct Rejection” [CR]). For example, the description of the Hit in the general intelligence condition read as follows:
“Harry recently took a test designed to assess his general intelligence. When asked to report how he thought he did, he responded, ‘better than the average person.’ In fact, it turns out that he actually did beat the average overall score on the general intelligence test.”
Each target was presented on a single page and the order of the four targets was randomized for each participant. All target names were male, which simplified the study design, but leaves open potential moderator effects of gender.
Participants were asked to rate each target on three trait adjectives comprising a scale for the domain of competence (intelligent, rational, and naïve [reverse scored]), and in addition, they rated the person on the adjective “competent” itself. Respondents also rated each target on three trait adjectives related to the domain of morality (ethical, trustworthy, and selfish [reverse scored]), and in addition, also rated the target on the adjective “moral” itself. Previous research has shown that these two scales are sufficiently reliable and independent of each other (Krueger & Acevedo, 2007; Krueger & DiDonato, 2010). All ratings were made on a scale from 1 (= not at all) to 5 (= extremely). Trait adjectives were presented on a single page below the target description and were randomized for each participant. After completing their ratings, participants were directed to a debriefing page and given a code to enter into MTurk indicating that they completed the task.
Results
Analytical Strategy and First Findings
The data for Study 1 are available as Electronic Supplementary Material, ESM 2. Ratings for each target were aggregated into unweighted averages to represent the dimensions of competence (intelligent, rational, naïve [reverse scored]) and morality (ethical, trustworthy, and selfish [reverse scored]). As expected, these scales were correlated with their respective single-rating adjective measures of them (competent, r = .65; moral, r = .70). Both scales had satisfactory reliability (mean inter-item correlations = .38 [α = .63] and .48 [α = .72], respectively, for competence and morality). The two scales were only modestly correlated with each other over respondents and within- and between-conditions, r(790) = .31.
We began the hypothesis tests with a set of four two-way analyses of variance (ANOVAs) with repeated measures on both variables (reality and perception). To take the correlation between the two judgment dimensions into account, we then also performed four analyses with repeated covariates (ANCOVAs; Tabachnick & Fidell, 2007, pp. 214–215). In all resulting figures, raw means are shown as columns and the adjusted means are shown as “ghost columns.” To anticipate a critical result, the findings were similar regardless of the analytic approach, and we therefore refer to ANCOVA results only when they departed from the conventional analysis. More detailed information on the consistency of these analytic tests can be found in the Electronic Supplementary Material, ESM 1. To represent effect sizes for main and simple effects, we used Cohen’s index d, a well-known and readily interpretable metric in standard units, in addition to the ηp2 index routinely provided by the SPSS software.
The differences between and among the four conditions are apparent in the graphed means and the variation in the inferential statistics. Although we also performed omnibus analyses including type of test and dimension of judgment in the same statistical model, we do not report these findings here because they do not affect any conclusions drawn from the focused analyses.
Judged Competence After Intelligence Test
For targets who had taken a general intelligence test, we predicted that Hits (H) would be perceived as most competent and that False Alarms (FA; or self-enhancement errors) would be perceived as least competent. The empirical pattern, as seen in Figure 1A, supported this hypothesis. Respondents judged above-average targets (H and M) as more competent than below-average targets (CR and FA), F(1, 98) = 197.19, p < .01, ηp2 = .67, d = 2.01. They also rewarded accuracy in self-perception (H + CR > FA + M), as shown by the significant interaction between the reality and the perception effect, F(1, 98) = 125.30, p < .01, ηp2 = .56. Simple comparisons showed that respondents judged those who correctly claimed to be above average (H) as far more competent than those who did so falsely (FA), F(1, 98) = 274.47, p < .01, ηp2 = .74, d = 2.36, but they did not differentiate between those who accurately claimed to be below average (CR) and those who falsely did so (M), F(1, 98) = 1.89, p < .17, ηp2 = .02. There was also a main effect of perception, F (1, 98) = 8.59, p < .01, ηp2 = .08, d = .42, which fell to nonsignificance in the ANCOVA.
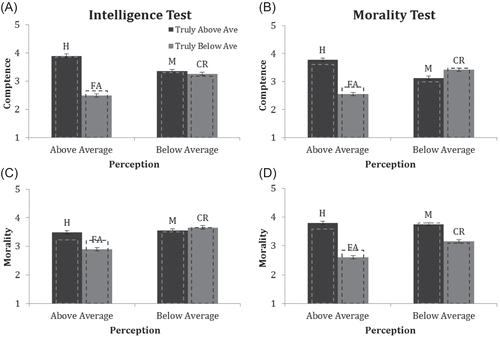
Judged Competence After Morality Test
When considering a person who had taken a morality test, a similar pattern emerged (Figure 1B). As expected, the effect of reality, F(1, 98) = 54.41, p < .01, ηp2 = .36, d = 1.07, and its interaction with the target’s self-perception, F(1, 98) = 126.76, p < .01, ηp2 = .56, were statistically significant and of medium size. Respondents judged those who made a self-enhancement error (FA) as less competent than those who were positively biased but correct (H), F(1, 98) = 205.03, p < .01, ηp2 = .699, d = 2.05. They also judged those who correctly perceived themselves to be below average (CR) as more competent than those who falsely claimed to be below average (M), F(1, 98) = 8.79, p < .01, ηp2 = .07, d = .42, which was unexpected. The main effect of the target’s self-perception was significant, F(1, 98) = 5.83, p < .01, ηp2 = .06, d = .35, but this effect disappeared in the ANCOVA. Taken together, these data suggest that respondents not only rewarded high performance but also accurate self-perception with high ratings of competence.
Judged Morality After Intelligence Test
For morality judgments about a target person’s perceived and actual performance on an intelligence test, we predicted that respondents would value a target’s modesty. Consistent with this hypothesis, the main effect of perception was significant, F(1, 98) = 59.49, p < .01, and large, ηp2 = .38, d = 1.10 (see Figure 1C, for the pattern of means). This effect was qualified by an interaction with the test result, F(1, 98) = 54.42, p < .01, ηp2 = .36, such that targets committing a self-enhancement error were judged especially harshly. Hits (H) were perceived as more moral than False Alarms (FA), F(1, 98) = 59.68, p < .01, d = 1.10, but Correct Rejections (CR) were not perceived as more moral than Misses (M) after correcting for multiple comparisons, F(1, 98) = 5.19, p < .026, d = .32. This interaction vanished in the ANCOVA. Likewise, only the raw data revealed a main effect of reality, F(1, 98) = 29.49, p < .01, ηp2 = .23, d = .78.
Judged Morality After Morality Test
For judgments of morality, we predicted that the target’s performance on a morality test would dominate. This hypothesis was also supported. Figure 1D shows that performance on a moral test determines how a person is seen on the dimension of morality, F(1, 98) = 183.10, p < .01, ηp2 = .65, d = 1.93. Targets who claimed to be more moral than average were judged as less moral than those who claimed to be less moral, F(1, 98) = 21.56, p < .01, ηp2 = .18, d = .66. There was also a significant interaction between reality and perception, F(1, 98) = 33.66, p < .01, ηp2 = .26. Unpacking this interaction, we found that self-enhancement errors (FA) were judged more harshly than correct modesty (CR), F(1, 98) = 41.60, p < .01, ηp2 = .27, d = .92. Respondents did not discriminate between true positives (H) and self-effacement errors (M).
Discussion
The findings of Study 1 show the importance of considering the domain in which targets assess themselves and the dimension observers use to judge them. The dimension of judgment appears to be more important than the dimension of self-perception and performance. When observers judge competence, they reward both the target’s performance and the accuracy of self-perception. When they judge morality, they punish self-enhancement bias, and they do not reward correct self-enhancement. Finally, when the domain of self-perception and performance is morality, observers are most sensitive to the test results.
We designed a second study with two objectives in mind. First, we wanted to test the replicability of two key findings: the interactive effect of perception and reality on competence judgments and the negative effect of self-enhancement bias on morality judgments. Second, we wanted to compare the judgments of the four discrete types of targets (H, FA, M, CR) with judgments of trimmed targets, that is, targets for whom only information regarding their self-perception or only information regarding their test performance was available. In this study, we presented all respondents with targets who had taken a test of general intelligence.
Study 2
In most respects, the design, the procedures, and the analytical approach were the same as the ones used in Study 1. The main extension was the addition of baseline targets. Some respondents judged targets who thought they scored better (or worse) than average, while no true score information was available. These cases model the social-comparison paradigm in that only comparative self-perception information is available. These respondents also judged targets about whom only their performance was known, that is, cases that capture a critical element of the social-reality paradigm. These modifications afford tests of two additional hypotheses: First, self-enhancement bias may lower judgments of morality even when respondents cannot tell whether there was a self-enhancement error. Second, low performance may not only lower judged competence but also judged morality (a halo effect).
Method
Participants
Participants (N = 200) were recruited on Amazon Mechanical Turk (MTurk; Amazon, 2014), resulting in 100 participants per sample. As in Study 1, TurkGate (2013) software ensured that respondents had not contributed to earlier studies. Participants received $0.30 for completing the task (mean completion time 3:53). No demographic information was collected. The data of two participants were excluded from analysis because all ratings were the midpoint of the scale. Hence, there were data from 198 participants in total. Power estimates for tests of correlated means were the same as in Study 1. For comparisons of independent samples, mean differences of d = .40 and .46 would, respectively, be significant with a probability of .80 or .90.
Procedures and Design
All survey materials were presented online using Qualtrics survey software (Qualtrics, 2013). Eligibility to complete the survey was restricted to individuals residing in the United States. All participants gave informed consent. They were told that they would rate four target individuals who completed a test of general intelligence and subsequently exhibited some judgment or behavior.
Participants assigned to the experimental condition (n = 99) received complete information about the targets: the materials and the procedures were the same as in Study 1, although all participants were told that targets had completed a test of general intelligence. Participants in the control condition (n = 99) received only one piece of information regarding either the target’s performance (reality) or self-judgment (perception). These participants judged four targets who thought they had performed better than average on the test (high perception), thought they had performed worse than average (low perception), had indeed performed better than average (high reality), or had performed worse than average (low reality). It was emphasized that these trimmed targets, who perceived themselves as better or worse than average, did not know their actual scores. Each target was presented to participants on a single page and the order of these pages was randomized for each participant.
All participants were instructed to rate each target on the six trait adjectives representing facets of competence and morality. After completing their ratings, participants were directed to a debriefing page and given a completion code to enter into MTurk indicating that they completed the task.
Results
The data for Study 2 are available as Electronic Supplementary Material, ESM 3. The two scales again showed satisfactory reliability (mean inter-item r = .31 [α = .50] and .48 [α = .69], respectively, for competence and morality,3 and the scale scores were moderately correlated with each other, r(394) = .51 and .35, respectively, in the experimental and the control condition. We again performed both ANOVA and ANCOVA, and display both raw and adjusted means (see Figures 2 and 3).
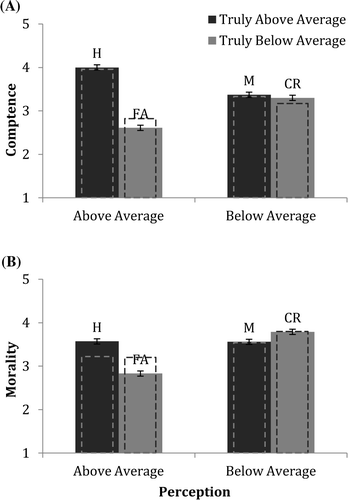
Judgments of Fully Described Targets
The pattern of results for competence judgments in the experimental condition was similar to that found in Study 1 (Figure 2A). The key hypothesis was supported by the interaction between perception and reality, F(1, 98) = 132.21, p < .01, ηp2 = .57. Targets correctly claiming to be above average (H) were judged most favorably, and targets committing a self-enhancement error (FA) were judged least favorably, F(1, 98) = 230.64, p < .01, ηp2 = .70, d = 2.17. There was no difference between those who claimed to be below average, such that those who were incorrect (M) were perceived as no more competent than those who were correct (CR), F(1, 98) = 1.73. Together, above-average targets (H and M) were rated as more competent than below-average targets (FA and CR), F(1, 98) = 153.95, p < .01, ηp2 = .61, d = 1.77, while the main effect of perception was not significant, F(1, 98) = .41 (although it was in the ANCOVA).
Morality judgments also replicated the pattern found in Study 1 (Figure 2B). Here the critical finding was that respondents were sensitive to the target’s self-perception, judging self-enhancers (H, FA) more negatively than self-effacers (M, CR), F(1, 98) = 47.01, p < .01, ηp2 = .32, d = .98. They were also sensitive to performance, judging above-average performers more favorably than below-average performers, F(1, 98) = 20.70, p < .01, ηp2 = .18, d = .65. There was also an interaction between perception and reality, F(1, 98) = 58.16, p < .01, ηp2 = .37. Respondents judged targets who correctly considered themselves below average (CR) as more moral than targets who did so incorrectly (M), F(1, 98) = 7.35, p < .01, ηp2 = .07, d = .38, an effect not seen in Study 1. Stated differently, respondents penalized false modesty. Finally, there was a large difference between the two targets who claimed to be better than average (H > FA), F(1, 98) = 69.23, p < .01, ηp2 = .41, d = 1.19, but this effect disappeared in the ANCOVA.
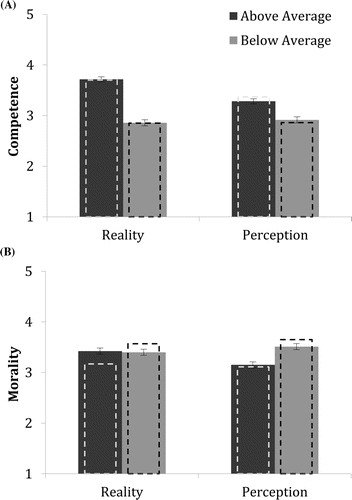
Judgments of Trimmed Targets
Turning to the control condition, we expected that targets who scored above average on an intelligence test should be seen as more competent than targets who did not. It was less clear, however, if this should also hold true for targets who merely claimed to be above average. It might turn out that when true performance is unknown, targets who claim to be better than average are judged as more competent than targets who do not (Anderson, Brion, Moore, & Kennedy, 2012; Lamba & Nityananda, 2014). The reason is that respondents may – correctly – assume that reality and perception are positively correlated.4 If so, a self-enhancer is more likely to be a H than a FA and should be rewarded with a high competence rating. We expected the effect of reality to be larger than the effect of perception because correlations between reality and perception are imperfect. The findings (see Figure 3A) indeed showed a large effect of reality, F(1, 98) = 78.74, p < .01, ηp2 = .45, d = 1.27. There was also an effect of perception favoring the self-enhancers, F(1, 98) = 16.75, p < .01, ηp2 = .15, d = .59.5 In other words, a person showing a self-enhancement bias deserves the benefit of the doubt because the self-prediction is more likely correct than incorrect.
For judgments of morality (see Figure 3B), our critical prediction was that self-enhancers would be judged as less moral than targets without this bias. This turned out to be the case, F(1, 98) = 6.90, p < .01, ηp2 = .07, d = .38. There was no effect of reality, F(1, 98) = 2.20, p < .14.
Comparing Judgments of Partially and Fully Described Self-Enhancers
Central to this research is the idea that it is critical to distinguish between those whose self-enhancing perceptions are vindicated by reality (H) and those whose errors are revealed (FA). For fully described targets, judgments of competence showed an interaction between perception and reality, which the social-comparative or the social-reality effect could explain neither individually nor jointly. We therefore made direct comparisons between judgments of H and FA targets and their trimmed analogs.
The findings for H targets are displayed in Figure 4B. It is noteworthy that respondents judged a successful self-enhancer (H) as more competent (M = 4.0) than a self-enhancer whose performance was still unknown (M = 3.37), t(196) = 8.72, p < .01, d = 1.08, or a successful target whose self-perception was unknown (M = 3.71), t(196) = 3.77, p < .01, d = .54. This pattern supports the idea that judgments of competence are an additive function of perception (self-confidence) and reality (high performance). Judgments of morality showed a similar, though attenuated, pattern. H targets (M = 3.57) were judged as more moral than those who merely claimed to be better than average (M = 3.15), t(196) = 4.37, p < .01, d = .71, and as marginally more moral than above-average performers (M = 3.42), t(196) = 1.83, p < .07, d = .26.6
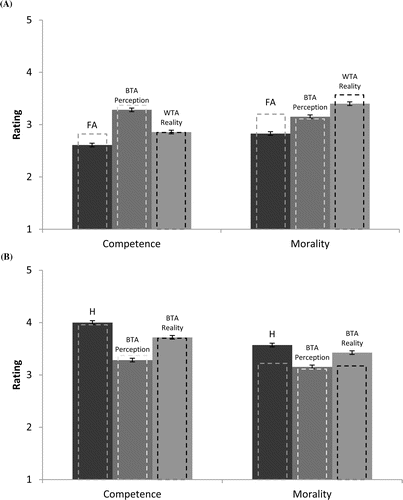
The other side of the self-enhancement coin is error. The findings for FA targets are displayed in Figure 4B. The FA target was judged as less competent (M = 2.61) than someone who merely claimed to be above average, (M = 3.28), t(196) = 7.60, p < .01, d = 1.10, and as less competent than a below-average target of unknown self-perception (M = 2.86), t(196) = 3.07, p < .05, d = .44.7 Finally, the FA target was judged as less moral (M = 2.83) than a self-enhancer of unknown performance (M = 3.15), t(196) = 3.43, p < .05, d = .49,8 and as far less moral than a below-average target of unknown self-perception (M = 3.40), t(196) = 6.74, p < .01, d = .96.
Inspection of the data also revealed an unexpected difference in the judgments of fully and partially described targets. Targets claiming to be below average were rated as less competent (M = 2.92) than similar claimants whose perceptions were known to be either correct, M = 3.30, t(196) = 5.04, p < .01, d = .72, or incorrect, M = 3.37, t(196) = 5.97, p < .01, d = .85. This pattern suggests a subtle and novel bias: fully described self-effacers attracted comparatively favorable competence ratings regardless of whether their performance matched or deviated from their self-judgment. If their self-effacing predictions turned out to be correct, these individuals were judged as competent thanks to their accuracy. Conversely, if self-effacing predictions turned out to be incorrect, these individuals were also judged as competent thanks to their test performance. This pattern holds an intriguing lesson for a person of low self-confidence. The winning strategy might be to abstain from making any self-related assessment unless objective results are at hand. Interestingly, judgments of morality did not show this pattern. Respondents only judged CR (M = 3.79), but not M (M = 3.56), as more moral than those who simply perceived themselves to be worse than average (M = 3.51), t(196) = 3.08, p < .01, d = .44; t(196) = .516.
Discussion
The results of Study 2 tracked those of Study 1. For fully described targets, observer judgments were sensitive to perception and reality information and to the dimension of evaluation. Judgments of competence depended on both test performance and the accuracy of self-prediction. Observers clearly discriminated between correct and incorrect self-enhancement. In contrast, judgments of morality depended mainly on the direction of the target’s self-perception. Observers judged both correct and incorrect self-enhancers negatively.
Judgments of trimmed targets further supported the idea that in the domain of competence, both the target’s self-perception and performance matter. When judging the competence of targets described only by their performance or only by their self-perception, observers seemed mindful of the general accuracy of self-perception (Zell & Krizan, 2014); they assumed that a self-enhancer’s claim is more likely to be true than false (see also Anderson et al., 2012; Kennedy, Anderson, & Moore, 2013). Finally, self-enhancement bias was associated with reduced judgments of morality.
General Discussion
In this research, we explored the utility of a decision-theoretic approach to the study of perceptions of self-enhancement. We found that observers judge self-enhancers to be highly competent when performance data support a positive self-perception and even when no performance data are available. In contrast, they attribute low competence to individuals who display erroneous self-enhancement. Judgments of the target person’s morality are less modulated by performance data. Observers react mainly, and negatively, to self-enhancement bias, be it correct or incorrect. Taken together, these patterns help explain findings obtained by Anderson et al. (2012) and Hoorens et al. (2012). Anderson et al. found positive reputational effects in judgments of competence in a performance domain. Hoorens et al. found negative effects in a domain of interpersonal relations and the claimant’s work ethic, both of which are highly saturated with implications for perceived morality. Both sets of findings can be situated within the decision-theoretic framework.
Implications and Limitations
One important question is why self-enhancement bias is so common when there is a considerable risk of being judged poorly by observers. One possibility is that individuals do not fully realize what impression they make. When they are focused on the positivity of their self-assessment and how they might compare with others, the impressions they make on third parties may fade from view. A more subtle possibility is that individuals are sensitive to the impression their comparative self-assessments make on others, but care more about the dimension of competence (Wojciszke, 2005). Here, individuals can improve the impressions they make by claiming to be better than average, despite the risk of committing a FA. If these individuals are not obligated to provide evidence to support their claims, this is an adaptive strategy. The context of the task may explain why this is so. When people wonder how they compare with others on an issue of interest (performance on a task or possession of a desirable trait), they enter a relative and perhaps even competitive frame of mind (Tesser, 1988). Such a frame lines up well with the question of competence, which is often cast in relative terms, but does not translate well to the domain of morality, which is often framed in terms of absolutes (Baron, 2012). This creates an interesting paradox where individuals tend to see themselves as more moral than average yet are inexperienced in directly comparing morality between others, or in constructing a notion of “average” morality to begin with. Yet, observers appear willing to denigrate these “morality-enhancing” targets despite lacking a clear image of what such enhancement might look like or indicate.
Individuals are likely conflicted when faced with the task of whether or not to claim self-superiority. On the one hand, doing so improves perceptions of their competence; on the other hand, it diminishes their perceived morality. Our data show this dilemma in Experiment 2 (control condition; Figures 3A and 3B, rightmost bars), where claiming to be better than others was seen as more competent, and less moral, than claiming to be worse. What drives this difference between perceptual domains? Morality has recently been conceptualized as part of the “essential” self and is a key determining factor in lay perceptions of “what a person is really like” (Hartley et al., 2016; Strohminger & Nichols, 2014). Similarly, morality is more important to observers than competence (Goodwin et al., 2014). It may be the case that more is at stake in the moral domain when making social-comparative claims. Hubristic or arrogant individuals may also be seen as morally corrupt or tainted (Rozin & Nemeroff, 1990), which may serve as a cue that these individuals will continue to behave in unappealing, self-superior ways. Another possibility is that the two domains are asymmetrically weighted in how observers respond to social-comparative claims. If it is the case that negative information looms larger in the moral domain and positive information is more important in the competence domain (i.e., Klein & Epley, 2016; Reeder & Brewer, 1979; Skowronski & Carlston, 1989), then it is sufficient to argue that one negative observation (a better-than-average claim) and one positive observation (performing better than average) should result in low morality and high competence.
There does not seem to be a unitary answer to the question of whether self-enhancement is an adaptive strategy. The domain of self-perception, the dimension of judgment, and the presence of outcome information are all relevant. This three-dimensional space makes the individual’s decision to self-enhance challenging and research on the resulting reputations complex. Ideally, a potential self-enhancer would know the results of such research before making a decision. Lacking such information, the perceiver must rely on heuristics.
Although the current research sheds new light on the social perception of self-enhancement, the present studies are only a beginning. In Study 2, for example, we did not pursue the domain of moral performance. We focused on the domain of competence in order to probe the hypotheses with greater depth in one area. Likewise, the present findings are limited to perceptions of male targets. Self-enhancing women may be perceived differently. For example, it has been shown that dominant and task-motivated women are seen as less likable, less competent, and more threatening than similar men (Carli, LaFleur, & Loeber, 1995).
Self-Enhancement as a Strategic Choice
Despite these limitations, we now offer some conjectures about the choices available to social actors. How might they take anticipated social impressions into consideration when deciding how to present themselves? On the one hand, the morality effect suggests caution; on the other hand, the possibility of being proven correct after having made a self-enhancing claim raises the prospect of gaining the prestige of high competence. Staking one’s bet on having a positive self-evaluation vindicated is a good strategy inasmuch as the accuracy correlation between perception and reality is positive.
What happens, however, when people choose to self-enhance in an effort to exploit this accuracy correlation? If everyone self-enhances, or if no one does, this correlation remains unaffected. With intermediate numbers of self-enhancers, however, the correlation drops.9 In other words, self-enhancement can be self-limiting at the group level because it undermines a key incentive to self-enhance.10 This result highlights a general issue of magical thinking. When individuals change their judgments or behaviors because they are correlated with a desirable outcome but without having causal power over this outcome, they engage in self-signaling (Mijović-Prelec & Prelec, 2010). They may conclude, for example, “now that I have raised my expectations, success is more likely, because overall, expectations and success are positively related.” Individuals who self-enhance because they believe a positive self-view makes a positive self more likely – when there is no causal effect – are deceiving themselves (Von Hippel & Trivers, 2011). In contrast, individuals who merely self-enhance in order to maximize reputational payoffs are reasoning rationally. Still, it remains true that if every other individual self-enhances with the goal to be seen as competent, the accuracy correlation will be lower than it would be without this increase in self-enhancement. We must acknowledge, therefore, that two normative principles of rationality, value maximization and accuracy, can be in conflict.
Going further, we can ask what would happen if each individual faced the choice to self-enhance while knowing that others have the same choice. There is now a social dilemma (Dawes, 1980; Van Lange, Joireman, Parks, & Van Dijk, 2013). Individuals motivated by truth and accuracy might prefer a world in which half of the group correctly self-enhance and they themselves are part of this half, whereas egocentrically motivated individuals might prefer a world in which they are among a small number of self-enhancers enjoying a social status gain. Egocentric individuals would find little comfort knowing that everyone self-enhances. Yet, each individual would be tempted to self-enhance, hoping that others would not. When everyone responds to the same incentive, the result is the inefficient and unpleasant outcome of widespread self-enhancement.
To appreciate the potential dilemma faced by self-enhancers, consider the argument that the give and take of praise and esteem within a social group can be modeled as a prisoner’s dilemma (Krueger, Vohs, & Baumeister, 2008). The group is happiest if all give and receive esteem; yet, each individual is motivated to withhold esteem in hopes of rising to the top of the group assuming that some will continue to cooperate and provide esteem. The self-enhancement dilemma is similar, but it might be best described as a game of chicken (Rapoport & Chammah, 1966). Imagine two braggarts in a mutual challenge (“You think you’re better than me!?”). If both choose to throw down this gauntlet (defect), neither will likely be satisfied. If both suppress the challenge, they can live in comparative (and cooperative) peace. If one claims social status by declaring to be better than the other and the other submits, the defector wins, but the cooperator is still able to avoid a costly confrontation. Eventually, claims of self-superiority must be backed up by reality. If not, the social group will learn that the self-enhancer committed an error, thus diminishing their perceived competence and morality.
The family resemblance between self-enhancement and social defection reveals its dark side. Whereas simple, non-comparative self-esteem depends on social approval (MacDonald, Saltzman, & Leary, 2003), self-enhancement shortcuts the immediate need for social validation. Particularly in the moral domain, where avoidance of self-enhancement is the prudent choice, a self-enhancer attempting to raise himself above others is likely unconcerned with reputational damage. As Paulhus (1998) and Robins and Beer (2001) have shown, disapproval will eventually come, especially when self-enhancement is publicly displayed (Hoorens et al., 2012). When reputation-relevant feedback is ignored, self-enhancement for the sake of short-term gains is a case of temporal discounting or myopia (Moore & Kim, 2003).
Conclusions
We have moved from considering self-enhancement as a social-comparative judgment to treating it as a decision problem and to placing this decision in a social context of others who are similarly motivated. Incorporating reputational concerns into the study of self-enhancement raises new questions. How deep is the analogy between self-enhancement and social defection? What does this analogy imply for the role of intuitive and reflective social reasoning? Recent research suggests intuitive and reflective thinking are differentially associated with prosocial and self-regarding choices (Evans, Dillon, & Rand, 2015). We suspect that self-enhancement can be, depending on the context, not only a matter of automatic egotism (Hoorens, 2014), but also a strategic choice. Of course, the line between automaticity and deliberate strategy is often blurred in real life. We opened this article with a recent quote from presidential hopeful Donald Trump, who to some represents the image of a charismatic and powerful leader, and to many others the image of a hubristic narcissist. Who better to put the paradox of humility into sharp relief?
Electronic Supplementary Material
The electronic supplementary material is available with the online version of the article at http://dx.doi.org/10.1027/1864-9335/a000287
- Additional analyses.
- Raw data for Study 1.
- Raw data for Study 2.
1But see Dufner et al. (2013) who found support for the adaptiveness of self-enhancement using measures of self-overestimation.
2A special issue edited by Abele et al. (2008) provides an in-depth treatment of theory and findings relevant to the two-dimension framework of social perception.
3The low reliability in competence ratings was due primarily to the adjective “Naïve.” Removing this item from analyses caused no notable changes in the results or interpretations; all reported results include this item.
4Lamba and Nityananda (2014) suggest that observers are deceived by inflated self-judgments. For this argument to be compelling, observers would need direct access to true scores, which they did not have in the Lamba and Nityananda study or ours. Otherwise, observers take the target’s self-perception as the only available cue, a heuristic strategy that does not imply self-deception.
5This conclusion was upheld by a significant interaction term in a 2 (above average vs. not) by 2 (reality vs. perception) ANOVA, F(1, 98) = 24.40, p < .01, ηp2 = .199.
6These last two comparisons were not significant in ANCOVA.
7Not significant in ANCOVA.
8Not significant in ANCOVA.
9We tested and confirmed this conjecture with a computer simulation.
10The curvilinear pattern we observed is specific to the correlational measure of accuracy (Dunning & Helzer, 2014). If accuracy is indexed by the average absolute difference between estimate and criterion, inaccuracy increases linearly with the number of self-enhancers in the group.
References
(2008). Fundamental dimensions of social judgment. Special Issue of European Journal of Social Psychology, 38, 1063–1065. doi: 10.1002/ejsp.574
(2005).
The better-than-average effect . In M. D. AlickeD. A. DunningJ. I. KruegerEds., The self in social judgment (pp. 85–106). New York, NY: Psychology Press.. (2011). Handbook of self-enhancement and self-protection. New York, NY: Guilford.
(2008). Punishing hubris: The perils of overestimating one’s status in a group. Personality and Social Psychology Bulletin, 34, 90–101. doi: 10.1177/0146167207307489
(2012). A status-enhancement account of overconfidence. Journal of Personality and Social Psychology, 103, 718–735. doi: 10.1037/a0029395
(2012).
Where do non-utilitarian moral rules come from? . In J. I. KruegerEd., Social judgment and decision-making (pp. 261–278). New York, NY: Psychology Press.(1995). Nonverbal behavior, gender, and influence. Journal of Personality and Social Psychology, 68, 1030–1041. doi: 10.1037/0022-3514.68.6.1030
. (2016, July 17). The Republican Ticket: Trump and Pence. http://www.cbsnews.com/news/60-minutes-trump-pence-republican-ticket/
(1995). Overly positive self-evaluations and personality: Negative implications for mental health. Journal of Personality and Social Psychology, 68, 1152–1162. doi: 10.1037/0022-3514.68.6.1152
(1980). Social dilemmas. Annual Review of Psychology, 31, 169–193. doi: 10.1146/annurev.ps.31.020180.001125
(2013). Are actual and perceived intellectual self-enhancers evaluated differently by social perceivers? European Journal of Personality, 27, 621–633. doi: 10.1002/per.1934
(2014). Beyond the correlation coefficient in studies of self-assessment accuracy: Commentary on Zell & Krizan. Perspectives on Psychological Science, 9, 126–130. doi: 10.1177/1745691614521244
(2015). Fast but not intuitive, slow but not reflective: Decision conflict drives reaction times in social dilemmas. Journal of Experimental Psychology: General, 144, 951–966. doi: 10.1037/xge0000107
(2004). Perceptions of humility: A preliminary study. Self and Identity, 3, 95–114. doi: 10.1080/13576500342000077
(2007). G*power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39, 175–191. doi: 10.3758/BF03193146
(2013). TurkGate (Version 0.4.0) [Software]. Retrieved from http://gideongoldin.github.com/TurkGate/
(2014). Moral character predominates in person perception and evaluation. Journal of Personality and Social Psychology, 106, 148–168. doi: 10.1037/a0034726
(2016). Morality’s centrality to liking, respecting, and understanding others. Social Psychological and Personality Science, Advance online publication. doi: 10.1177/1948550616655359
(2015). Self-enhancement diminished. Journal of Experimental Psychology: General, 144, 1003–1020. doi: 10.1037/xge0000105
(2014). What’s really in a name-letter effect? Name-letter preferences in indirect measures of self-esteem. European Review of Social Psychology, 25, 228–262. doi: 10.1080/10463283.2014.980085
(2012). The Hubris hypothesis: You can self-enhance, but you’d better not show it. Journal of Personality, 80, 1237–1274. doi: 10.1111/j.1467-6494.2011.00759.x
(1994). Accuracy and bias in self-perception: Individual differences in self-enhancement and the role of narcissism. Journal of Personality and Social Psychology, 66, 206–219. doi: 10.1037/0022-3514.66.1.206
(2013). When overconfidence is revealed to others: Testing the status-enhancement theory of overconfidence. Organizational Behavior and Human Decision Processes, 122, 266–279. doi: 10.1016/j.obhdp.2013.08.005
(2016). Maybe holier, but definitely less evil, than you: Bounded self-righteousness in social judgment. Journal of Personality and Social Psychology, 110, 660–674. doi: 10.1037/pspa0000050
(2007). Perceptions of self and other in the prisoner’s dilemma: Outcome bias and evidential reasoning. American Journal of Psychology, 120, 593–618.
(2010). Perceptions of morality and competence in (non)interdependent games. Acta Psychologica, 134, 85–93. doi: 10.1016/j.actpsy.2009.12.010
(2013). Comparisons in research and reasoning: Toward an integrative theory of social induction. New Ideas in Psychology, 31, 73–86. doi: 10.1016/j.newideapsych.2012.11.002
(2008). A matter of trust: From social preferences to the strategic adherence to social norms. Negotiation & Conflict Management Research, 1, 31–52. doi: 10.1111/j.1750-4716.2007.00003.x
(2008). Is the allure of self-esteem a mirage after all? The American Psychologist, 63, 64–65. doi: 10.1037/0003-066X.63.1.64
(1999). Lake Wobegon be gone! The “below-average effect” and the egocentric nature of comparative ability judgments. Journal of Personality and Social Psychology, 77, 221–232. doi: 10.1037/0022-3514.77.2.221
(2004). Reconceptualizing individual differences in self-enhancement bias: An interpersonal approach. Psychological Review, 111, 94–110. doi: 10.1037/0033-295X.111.1.94
(2015). On the perceived intentionality of self-enhancement. The Journal of Social Psychology, 156, 28–42. doi: 10.1080/00224545.2015.1041447
(2014). Self-deceived individuals are better at deceiving others. PLoS One, 9, e104562. doi: 10.1371/journal.pone.0104562
(2000).
The nature and function of self-esteem: Sociometer theory . In M. ZannaEd., Advances in experimental social psychology (Vol. 32, pp. 1–62). San Diego, CA: Academic Press.(2003). Social approval and trait self-esteem. Journal of Research in Personality, 37, 23–40. doi: 10.1016/S0092-6566(02)00531-7
(2010). Self-deception as self-signaling: A model and experimental evidence. Philosophical Transactions of the Royal Society B: Biological Sciences, 365, 227–240. doi: 10.1098/rstb.2009.0218
(2007). Overconfidence and underconfidence: When and why people underestimate (and overestimate) the competition. Organizational Behavior and Human Decision Processes, 103, 197–213. doi: 10.1016/j.obhdp.2006.09.002
(2003). Myopic social prediction and the solo comparison effect. Journal of Personality and Social Psychology, 85, 1121–1135. doi: 1037/0022-3514.85.6.1121
(2007). Error and bias in comparative judgment: On being both better and worse than we think we are. Journal of Personality and Social Psychology, 9, 972–989. doi: 10.1037/0022-3514.92.6.972
(1984). Two-component models of socially desirable responding. Journal of Personality and Social Psychology, 46, 598–609. doi: 10.1037/0022-3514.46.3.598
(1998). Interpersonal and intrapsychic adaptiveness of trait self-enhancement: A mixed blessing? Journal of Personality and Social Psychology, 74, 1197–1208. doi: 10.1037/0022-3514.74.5.1197
. (2013). [Survey software]. Provo, UT: Qualtrics.
(1966). The game of chicken. American Behavioral Scientist, 10, 10–28. doi: 10.1177/000276426601000303
(1979). A schematic model of dispositional attribution in interpersonal perception. Psychological Review, 86, 61–79. doi: 10.1037/0033-295X.86.1.61
(2001). Positive illusions about the self: Short-term benefits and long-term costs. Journal of Personality and Social Psychology, 80, 340–352. doi: 10.1037/0022-3514.80.2.340
(1990).
The laws of sympathetic magic: A psychological analysis of similarity and contagion . In J. W. StiglerR. A. ShwederG. HerdtEds., Cultural psychology: Essays on comparative human development (pp. 205–232). New York, NY: Cambridge University Press.(2015). Good enough for an affair: Self-enhancement of attractiveness, interest in potential mates and popularity as a mate. European Journal of Personality, 30, 12–18. doi: 10.1002/per.2029
(1989). Negativity and extremity biases in impression formation: A review of explanations. Psychological Bulletin, 105, 131–142. doi: 10.1037/0033-2909.105.1.131
(2014). The essential moral self. Cognition, 131, 159–171. doi: 10.1016/j.cognition.2013.12.005
(2000). Psychological science can improve diagnostic decisions. Psychological Science in the Public Interest, 1, 1–26. doi: 10.1111/1529-1006.001
(2007). Using multivariate statistics (5th ed.). Boston, MD: Pearson Education.
(1988). Illusion and well-being: A social psychological perspective on mental health. Psychological Bulletin, 103, 193–210. doi: 10.1037/0033-2909.103.2.193
(2003). Portrait of the self-enhancer: Well adjusted and well liked or maladjusted and friendless? Journal of Personality and Social Psychology, 84, 165–176. doi: 10.1037/0022-3514.84.1.165
(2011). Complex social consequences of self-knowledge. Social Psychological and Personality Science, 2, 343–350. doi: 10.1177/1948550610390965
(2013). This examined life: The upside of self-knowledge for interpersonal relationships. PLoS One, 8, e69605. doi: 10.1371/journal.pone.0069605
(1988). Toward a self-evaluation maintenance model of social behavior. Advances in Experimental Social Psychology, 21, 181–228.
(2016). Why self-enhancement provokes dislike: The hubris hypothesis and the aversiveness of explicit self-superiority claims. Self and Identity, 15, 173–190. doi: 10.1080/15298868.2015.1095232
(2013). The psychology of social dilemmas: A review. Organizational Behavior and Human Decision Processes, 120, 125–140. doi: 10.1016/j.obhdp.2012.11.003
(2011). The evolution and psychology of self-deception. Behavioral and Brain Sciences, 34, 1–16. doi: 10.1017/S0140525X10001354
(2005). Morality and competence in person-and self-perception. European Review of Social Psychology, 16, 155–188. doi: 10.1080/10463280500229619
(2014). Do people have insight into their abilities? A metasynthesis. Perspectives on Psychological Science, 9, 111–125. doi: 10.1177/1745691613518075

