

Maschinelles Lernen zur Förderung von höheren Kompetenzen
Abstract
Zusammenfassung:Hintergrund: Die einschneidenden Veränderungen, welche moderne Gesellschaften durch die Digitalisierung erfahren haben, haben es unerlässlich gemacht, heutigen und künftigen Generationen höhere Kompetenzen als Rüstzeug für die neue Lern- und Arbeitswelt mitzugeben. Die Verwendung von digitalen Lernumgebungen zusammen mit maschinellem Lernen kann in diesem Kontext ein leistungsstarkes Werkzeug darstellen. Methoden: In der vorliegenden Übersichtsarbeit werden die Chancen und Herausforderungen von maschinellem Lernen im Bildungswesen anhand ausgewählter Anwendungsbereiche aufgezeigt. Zu jedem Anwendungsbereich wird eine Zusammenfassung der bestehenden Forschung präsentiert und die Anwendung anhand eines konkreten Beispiels aus der jüngsten Forschung veranschaulicht. Ergebnisse: Die Ergebnisse aus der jüngsten Forschung bestätigen, dass maschinelles Lernen ein enormes Potenzial hat, um das Bildungswesen durch personalisierte Lernmöglichkeiten für höhere Kompetenzen zu bereichern. Jedoch ist noch weitere Forschung nötig, um die wirkliche Lernwirksamkeit solcher Ansätze zu validieren.
Abstract:Background: The radical changes that modern societies have experienced through digitalization have made it essential to equip current and future generations with higher level competencies preparing them for the new world of learning and work. In this context, the use of digital learning environments together with machine learning can represent a powerful tool to train and assess these competencies. Methods: In this article, the opportunities, and challenges of machine learning in education are discussed based on a selection of use cases. For each use case, a summary of existing research is presented, and the corresponding application is illustrated with a specific example from recent research. Results: The results from recent research confirm that machine learning has an enormous potential to enrich education through personalized learning opportunities for higher competencies. However, more research is needed to validate the real effectiveness for learning of such approaches.
Einleitung
Der technologische Fortschritt der vergangenen Jahrzehnte hat zu vielen weitreichenden Veränderungen unseres alltäglichen Lebens geführt. Die Digitalisierung moderner Gesellschaften ist bereits im vollen Gange und hat viele Bereiche unseres Alltags erfasst. Eine Technologie, die in den Diskussionen um den Digitalisierungsprozess besonders häufig im Mittelpunkt steht, ist das maschinelle Lernen (engl. machine learning, kurz ML).
Maschinelles Lernen
ML kann als Sammlung von Methoden beschrieben werden, die es digitalen Systemen ermöglicht, mithilfe von selbstlernenden Algorithmen Zusammenhänge in existierenden Datensätzen zu erkennen und zukunftsrelevante Rückschlüsse zu ziehen (Welsch, Eitle & Buxmann, 2018). Der rasante Aufstieg von ML ist vor allem durch die konstant steigende Verfügbarkeit von digitalen Daten und eine immer höhere Rechenleistung moderner Computer begünstigt worden. Auf der einen Seite erlaubt ML den Anwender_innen Erkenntnisse aus großen Mengen von Daten zu gewinnen, die die menschlichen Kapazitäten bei weitem übersteigen. Des Weiteren können mithilfe von ML aus existierenden Daten statistische Modelle hergeleitet werden, die es erlauben, automatisiert Muster und Erkenntnisse für neue Daten zu extrahieren, ohne diese explizit zu programmieren (Welsch, Eitle & Buxmann, 2018). Diese Eigenschaften machen ML zu einem leistungsstarken Werkzeug, das bereits heute in vielen Bereichen Anwendung findet: sei es in der Medizin, wo ML für die Früherkennung von Krankheiten eingesetzt werden kann (Sajda, 2006), sei es zum Regulieren der Auslastung von Infrastruktur, wie beispielsweise in Verkehrsnetzen (Zantalis Koulouras, Karabetsos & Kandris, 2019), oder zur Optimierung der Energieversorgung (García-Martín, Rodrigues, Riley & Grahn, 2019). Ein weiterer beliebter Anwendungsbereich von ML-Methoden ist die Implementierung von automatisierten Empfehlungssystemen (engl. recommender systems), die z.B. im Onlinehandel (Wei, Huang & Fu, 2007), in Musik-Streamingdiensten (Schedl, Zamani, Chen, Deldjoo & Elahi, 2018), aber auch in sozialen Netzwerken (Eirinaki, Gao, Varlamis & Tserpes, 2018) zum Einsatz kommen. Besonders im Zusammenhang mit Letzterem haben sich in den vergangenen Jahren auch potenzielle Risiken von ML-Anwendungen gezeigt. Die negativen Auswirkungen der Digitalisierung auf moderne Gesellschaften, wie z.B. das Verbreiten von Fake News (Tandoc Jr, 2019), können durch einen unüberlegten Einsatz von ML noch erheblich verstärkt werden. In jüngster Zeit werden deshalb auch vermehrt Anstrengungen unternommen, um ML-Methoden transparenter und fairer zu gestalten (Mehrabi, Morstatter, Saxena, Lerman & Galstyan, 2021).
ML-Anwendungen in der Bildung
Ein Bereich, in dem der Einsatz von ML enorme Chancen bietet, aber auch potenzielle Risiken birgt, ist die Bildung. ML-Anwendungen im Bildungsbereich werden häufig (aber nicht ausschließlich) durch die Logdaten von digitalen Lernumgebungen ermöglicht (siehe Abbildung 1). Diese stellen eine detaillierte chronologische Repräsentation der Interaktionen der Lernenden mit einer digitalen Lernumgebung dar.
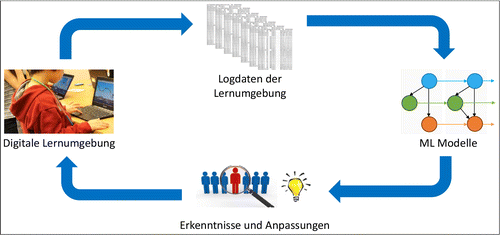
Beispielsweise lässt sich dann nachvollziehen, was Lernende wann angeklickt haben oder wo wie lange Zeit verbracht wurde. Anhand der Logdaten lässt sich daher im Nachhinein die gesamte Lernerfahrung der Lernenden rekonstruieren, was dann von Forschenden, Lehrenden und den Lernenden selbst genutzt werden kann, um wichtige Erkenntnisse zu gewinnen, welche im Gegenzug dabei helfen können, entsprechende Anpassungen zu implementieren. In den besten Fällen führt dies dann zu verbesserten Lernerfahrungen für die Lernenden. Die gesammelten Datensätze sind aber häufig so riesig, dass das Finden aller relevanten Verhaltensmuster allein durch menschliche Leistung nahezu unmöglich wäre. ML-basierte Analysen können hier Abhilfe schaffen, indem sie solche Aufgaben leistungsstarken Rechnern überlassen, die innerhalb kürzester Zeit viele Einblicke in große Datensätze geben können. In diesem Zusammenhang haben sich in der Vergangenheit zwei Forschungsstränge entwickelt, die es sich zur Aufgabe gemacht haben, den Querschnitt aus ML und Bildung zu untersuchen: Educational Data Mining (EDM) und Learning Analytics (LA). Das Hauptziel dieser Forschungsfelder ist es, Erkenntnisse aus Daten aus dem Bildungskontext zu gewinnen, um dann Entscheidungsfindungsprozesse im Bildungswesen zu unterstützen (Calvet Liñán & Juan Pérez, 2015). Auch wenn beide Forschungsfelder in den vergangenen Jahren immer mehr miteinander verschmolzen sind, lässt sich aus einer allgemeinen Perspektive sagen, dass EDM sich eher auf die technischen Methoden und LA sich eher auf die konkrete Anwendung im Bildungskontext konzentriert.
Die jüngsten Fortschritte in der EDM- und LA-Forschung haben die Umsetzung von adaptiven Lernumgebungen ermöglicht, welche sich kontinuierlich an die individuellen Bedürfnisse der Lernenden anpassen können. Bei diesen Anpassungen handelt es sich vor allem um Maßnahmen, die als besonders lernförderlich betrachtet werden, wie z.B. personalisiertes Feedback zum Lernprozess oder individualisierte Übungsempfehlungen basierend auf dem aktuellen Lernstand der Lernenden. Diese Maßnahmen können die Lernerfahrung für das Individuum erheblich verbessern, da Lernaktivitäten so besser auf das persönliche Niveau, Interesse und Lernverhalten abgestimmt werden können.
Eine Grundlage für solche personalisierten und adaptiven Lernerfahrungen bilden ML-basierte Methoden, die eine Modellierung des individuellen Lernstandes ermöglichen (Pelánek, 2017). Eine häufig verwendete Methode ist das sogenannte Knowledge Tracing, das oft in intelligenten Tutorensystemen (engl. intelligent tutoring system, kurz ITS) zum Einsatz kommt (Yudelson, Koedinger & Gordon, 2013). Über die Jahre wurden viele unterschiedliche Knowledge-Tracing-Ansätze entwickelt und mit verschiedensten Datensätzen aus digitalen Lernumgebungen zu Themen wie der Mathematik, dem Ingenieurswesen oder dem Sprachenlernen ausgewertet (Abdelrahman, Wang & Nunes, 2022). ITS verwenden den modellierten Lernzustand, um den Lernenden adaptive Unterstützung zu geben, z.B. in Form von personalisiertem Feedback während der Bearbeitung von Übungsaufgaben (Bimba, Idris, Al-Hunaiyyan, Mahmud & Shuib, 2017). In diesem Zusammenhang haben verschiedene Studien die Anwendung von personalisiertem Feedback in Kontexten wie dem Lernen von Mathematik (vgl. Arroyo et al., 2014), Sprachen (vgl. Heift & Schulze, 2007), Biologie (vgl. Olney et al., 2012) oder Informatik (vgl. Price et al., 2019) untersucht. Auf gleiche Weise kann die Modellierung des individuellen Lernstandes verwendet werden, um den Lernenden personalisierte Lernempfehlungen zu geben, z.B. durch die Auswahl der nächsten geeigneten Übungsaufgaben (Manouselis, Drachsler, Vuorikari, Hummel & Koper, 2011). Des Weiteren existieren Arbeiten, welche ML-basierte Methoden angewendet haben, um Erkenntnisse aus multimodalen Daten zu gewinnen. So wurden z.B. Bewegungserfassungssysteme zusammen mit biometrischen Sensordaten verwendet, um mithilfe von ML-Methoden fehlerhafte Bewegungen bei kardiopulmonalen Wiederbelebungsübungen zu erkennen (Di Mitri, Schneider, Specht & Drachsler, 2019), oder sie wurden in Kombination mit virtueller Realität verwendet, um bei Leibesübungen Echtzeit-Feedback zu geben (Hülsmann et al., 2019).
Die in dieser Übersichtsarbeit vorgestellten Methoden beruhen jedoch auf klassischen Interaktionsdaten aus digitalen Lernumgebungen (unter anderem sogenannte Clickstreamdaten), wie sie in Abbildung 1 dargestellt sind. Diese Art von Daten ist einfach zu erheben, da Interaktionen der Lernenden mit der Umgebung ohnehin notwendig sind, um die angebotene Lernaktivität überhaupt zu bearbeiten. Dies ermöglicht es zum einen, genügend große Datensätze zu erheben, was eine notwendige Voraussetzung ist, um ML-basierte Methoden anzuwenden. Zum anderen stellt die Analyse der aufgezeichneten Interaktionsdaten eine natürliche Art und Weise dar, um individuelle Lernvorgänge mit einem relativ feinen Detailgrad nachzuvollziehen. Bei guter Datenqualität und der Anwendung geeigneter ML-Methoden lassen sich so eher Erkenntnisse über Lernprozesse gewinnen als z.B. über schriftliche Prüfungen, die in den meisten Fällen nur das Produkt eines Lernvorgangs messen. Diese Eigenschaft ist besonders nützlich für das Erlernen höherer Kompetenzen wie z.B. den sogenannten 21st century skills (Van Laar, Van Deursen, Van Dijk & De Haan, 2017; Voogt & Roblin, 2010). Dieser Sammelbegriff fasst Kompetenzen wie z.B. Problemlösungsfähigkeit, selbstgesteuertes Lernen und Argumentationsfertigkeiten zusammen, die für künftige Generationen als unerlässlich betrachtet werden, um in modernen Lebens- und Arbeitswelten zu bestehen (vgl. Greiff et al. 2014; Noroozi, Dehghanzadeh & Talaee, 2020; Taranto & Buchanan, 2020). Das Lernen dieser Kompetenzen geht jedoch weit über den bloßen Erwerb von inhaltlichem Wissen hinaus und sie lassen sich im Allgemeinen auch nicht mehr durch klassische Lernkontrollen abprüfen. In diesem Zusammenhang kann die Kombination von digitaler Lernumgebung und ML-basierten Methoden einen großen Beitrag dazu leisten, solche Kompetenzen zu evaluieren und zu fördern. Die Erkenntnisse, die durch die Anwendung dieser Methoden sichtbar gemacht werden, können für Lernende, Lehrende und Forschende gleichermaßen hilfreich sein.
Nichtsdestotrotz ist es aber besonders im Bildungsbereich essenziell, dass ML-Anwendungen nachvollziehbar und transparent sind. Ein besonderes Risiko besteht beispielsweise dann, wenn die Vorhersagen und Empfehlungen solcher Modelle zu sehr auf das Verhalten von Mehrheitsgruppen abgestimmt sind und so als Folge suboptimale Lernmöglichkeiten für Minderheitsgruppen entstehen.
Mit Hinblick auf die vielen Chancen und Herausforderungen, welche ML-basierte Methoden für das Bildungswesen bieten, ist es das Ziel dieser Übersichtsarbeit, Praktiker_innen einen Überblick über die neuesten Entwicklungen in diesem Bereich zu geben. Zu diesem Zweck werden im Folgenden drei ausgewählte Anwendungsmöglichkeiten von ML-Methoden in der Bildung präsentiert, welche mit konkreten Beispielen und neuesten Ergebnissen aus der aktuellen Forschung veranschaulicht werden. Der Fokus liegt dabei speziell auf der Anwendung von ML zur Förderung von höheren Kompetenzen, welche für moderne Gesellschaften immer wichtiger werden: i) Forschungs- und Problemlösungskompetenzen, ii) die Kompetenz zum selbstgesteuerten Lernen und iii) Argumentationsfähigkeiten.
In den folgenden Abschnitten wird veranschaulicht, wie digitale Lernumgebungen in Verbindung mit ML verwendet werden können, um diese Kompetenzen zu fördern und zu evaluieren. In einer abschließenden Diskussion wird dann die Relevanz dieser Anwendungen für die Praxis und deren gegenwärtige Limitationen erörtert.
Ergebnisoffene Lernumgebungen für Forschungs- und Problemlösungskompetenzen
Ergebnisoffene Lernumgebungen und Forschendes Lernen
Ergebnisoffene Lernumgebungen (engl. open-ended learning environments, kurz OELEs) sind digitale Umgebungen, die es Lernenden ermöglichen, selbstständig naturwissenschaftliche Phänomene und die ihnen zugrundeliegenden Prinzipien zu erforschen. Basierend auf einem konstruktivistischen Lernansatz (Fosnot, 2013) werden interaktive Simulationen häufig im Zusammenhang des Forschenden Lernens (engl. inquiry-based learning) eingesetzt. Die konstruktivistische Lerntheorie basiert auf der Idee, dass Lernende sich Wissen am besten aneignen, wenn sie sich dieses selbstständig „konstruieren“, indem sie neue Erfahrungen und Erkenntnisse erfolgreich mit ihrem existierenden Vorwissen verknüpfen. Die Grundidee des Forschenden Lernens baut auf dieser Theorie auf und versucht, die Lernenden dabei in einen Lernvorgang einzubinden, der an wissenschaftlichen Forschungsvorhaben angelehnt ist. Entsprechend dem Modell von Pedaste et al. (2015) durchleben die Lernenden dabei einen Lernprozess mit fünf Hauptphasen (Orientierung, Konzeptualisierung, Untersuchung, Schlussfolgerung und Diskussion), der ihnen dabei helfen kann, wichtige Forschungs- und Problemlösungskompetenzen zu entwickeln. OELEs nehmen häufig die Gestalt von virtuellen Laboren an, in welchen die Lernenden frei mit unterschiedlichen Elementen und deren Parametern experimentieren können, um deren Einflüsse und Wirkungen zu untersuchen. Eine beliebte Umgebung für OELEs sind die PhET Interactive Simulations (Wieman, Adams & Perkins, 2008), die eine Vielzahl an Simulationen für verschiedene Bereiche anbieten, z.B. um elektrische Schaltkreise oder chemische Phänomene digital zu simulieren. Einige OELEs integrieren zudem bewusst spielerische Elemente, wie z.B. TugLet (Käser, Hallinen & Schwartz, 2017), eine Umgebung, die ein virtuelles Tauziehen simuliert, in welchem die Lernenden durch systematische Exploration die Stärken der unterschiedlichen Spielfiguren ermitteln müssen.
ML zur Analyse von OELEs-Logdaten
Im Gegensatz zu klassischen Lernkontrollen, die nur das Produkt eines Lernvorgangs messen, bieten OELEs die Möglichkeit, auch Einblicke in die Prozesse zu erhalten, mit denen die Lernenden die Phänomene verstehen und Probleme lösen, diee in solchen Umgebungen eingebettet sind (Land & Jonassen, 2012). Die bestehende Forschung hat sich insbesondere darauf konzentriert, mittels ML die Schlüsselfaktoren für ein lernförderliches Verhalten in OELEs zu identifizieren. So wurde z.B. in einer Studie mit knapp 100 Studierenden gezeigt, dass in einem OELE für elektrische Schaltungen bestimmte Aktionssequenzen (z.B. das Alternieren zwischen dem Testen von Schaltkreisen und dem bewussten Pausieren, um zu reflektieren) besonders lernförderliche Strategien darstellen (Perez et al., 2017). In einer anderen Arbeit wurde ein ML-Modell trainiert, das die Verhaltensmuster von knapp 2000 Sekundarschüler_innen in einem rollenspielbasierten OELE mit ihren Forschungskompetenzen in Zusammenhang stellt (Baker, Clarke-Midura & Ocumpaugh, 2016). Die ML-basierten Analysen offenbarten unter anderem, dass die Fähigkeit zum kritischen Lesen auch in interaktiven Umgebungen ein ausschlaggebender Faktor ist. In der Arbeit von Teig, Scherer und Kjærnsli (2020) wurden die Logdaten von über 1000 15-Jährigen analysiert, die an der PISA-Studie von 2015 teilgenommen haben. Ein Teil der Studie bestand darin, Aufgaben zu naturwissenschaftlichen Phänomenen mithilfe eines OELE zu lösen. Durch die Anwendung von ML-Methoden konnten die Autor_innen unterschiedliche Lernprofile identifizieren, die als strategisch, aufstrebend und unengagiert (engl. strategic, emergent und disengaged) klassifiziert wurden. In einer anderen Arbeit wurden die Logdaten von 99 Studierenden verwendet, um eine automatische Klassifizierung ihrer Problemlösungsstrategien in einer digitalen Chemie-Simulation zu erhalten (Gal, Uzan, Belford, Karabinos & Yaron, 2015). Die Autor_innen hoben unter anderem hervor, dass ein solcher Ansatz auch Lehrpersonen helfen kann, indem sie die individuellen Lernfortschritte der Schüler_innen einer Klasse sichtbar machen.
Beispiel: Forschendes Lernen im virtuellen Beer's Law Lab
Um den Leser_innen zu veranschaulichen, wie OELEs gemeinsam mit ML eingesetzt werden können, um Forschungs- und Problemlösungskompetenzen zu fördern, wird im Folgenden ein konkreter Anwendungsfall aus der jüngsten Forschung von Cock, Marras, Giang und Käser (2022) vorgestellt.
Lernumgebung und Aufgabe
In ihrer Studie verwendeten die Autor_innen das Beer's Law Lab der PhET-Simulationen, mit denen Lernende erforschen können, wie Licht in einer Lösung absorbiert wird und welche Faktoren die gemessene Extinktion beeinflussen (siehe Abbildung 2a). In dieser Umgebung können die Lernenden folgende Komponenten verändern: die Wellenlänge λ des Lichtstrahls, die Breite des Behälters (entspricht der Weglänge L des Lichts durch die Lösung), die Substanz der Lösung (welche sich in einer Änderung ihrer Farbe auswirkt) und die Konzentration c der Lösung. Durch das Experimentieren mit diesen Komponenten können die Lernenden im Idealfall das Lambert-Beer'sche Gesetz ableiten, das beschreibt, wie jeder dieser Parameter die gemessene Extinktion A beeinflusst: A = ϵλ · L · c.

Die Autor_innen haben dann eine Sortieraufgabe entwickelt, die von den Lernenden dann mittels des Beer's Law Lab gelöst werden musste (siehe Abbildung 2b). Den Lernenden wurden vier Behälter gezeigt, die sowohl in der Breite als auch in der Farbe und Konzentration der Lösung variierten. Darüber hinaus war die Wellenlänge des Lichtstrahls gegeben, mit denen die Extinktion der Behälter gemessen wurde. Die Aufgabe der Lernenden bestand nun darin, die vier Behälter nach der gemessenen Extinktion zu sortieren. Jedoch waren die gewählten Werte der vier Behälter nicht innerhalb des Wertebereichs der Simulation, sodass die Lernenden die richtige Sortierung nicht durch einfaches Einstellen und Ablesen der Werte finden konnten. Vielmehr mussten sie eine geeignete Problemlösungsstrategie finden, um systematisch die Einflüsse der verschiedenen Parameter zu erkennen und dann auf die richtige Sortierung zu schließen. Um jede der 24 möglichen Sortierungen nach dem Grad des damit verbundenen konzeptionellen Verständnisses zu klassifizieren, wurde ein baumbasierter Ansatz gewählt, der in einer früheren Arbeit von Cock, Marras, Giang und Käser (2021) vorgestellt wurde. Konkret wurde für jede Sortierung ermittelt, ob der Einfluss i) der Konzentration der Substanz, ii) der Breite des Behälters und iii) des Farbunterschieds zwischen Lichtstrahl und Lösung verstanden wurde oder nicht. Die Rangfolgen wurden dann nach der Anzahl der verstandenen Konzepte, die sie repräsentieren, gruppiert. Sortierungen, die 0 oder 1 verstandenes Konzept repräsentieren, wurden dann als limitiertes Verständnis bezeichnet, während Sortierungen, die 2 oder 3 verstandene Konzepte repräsentieren, als fortgeschrittenes Verständnis bezeichnet wurden.
Methoden
Die oben beschriebene Sortieraufgabe mit dem Beer's Law Lab wurde 448 angehenden Labortechniker_innen (43% weiblich) aus zehn verschiedenen Berufsschulen als Lernaktivität präsentiert. Die Aktivität wurde im Klassenzimmer als Teil einer regulären Unterrichtslektion und unter Aufsicht der Lehrperson durchgeführt. Die Auszubildenden lösten die Aufgaben eigenständig am Computer und für alle Teilnehmenden wurden die Logdaten in der Lernumgebung sowie ihre Antworten auf die Sortieraufgabe digital aufgezeichnet. Die Autor_innen trainierten dann verschiedene ML-Modelle mit dem Ziel, das konzeptuelle Verständnis einer lernenden Person (mittels der binären Klassifizierung limitiertes Verständnis und fortgeschrittenes Verständnis, siehe vorheriger Abschnitt) einzig anhand der Logdaten vorhersagen zu können. Die Modelle basierten dabei auf verschiedenen Implementierungen von sogenannten rekurrenten neuronalen Netzen (engl. recurrent neural networks, kurz RNNs). Konkret verwendeten die Autor_innen die Modelle GRU (engl. Abkürzung für gated recurrent unit) und SA-GRU (self-attention gated recurrent unit).
Ergebnisse
Die Autor_innen zeigten, dass es bereits nach einigen Interaktionen in der Lernumgebung möglich ist, das erworbene konzeptuelle Verständnis einer lernenden Person mit einer guten Genauigkeit vorherzusagen. Für die Evaluierung ihrer Modelle verwendeten die Autor_innen die sogenannte AUC-Metrik (engl. Abkürzung für area under the receiver operating characteristic curve), welche die Genauigkeit als Wert zwischen 0 = sehr ungenau und 1 = sehr genau wiedergibt. Die AUC-Werte der beiden verwendeten Modelle wurden dann nach steigender Anzahl an aufgezeichneten Interaktionen mit denen eines Random-Forest- (kurz RF) Basismodells verglichen.
Die Ergebnisse haben gezeigt, dass beide Modelle eine um bis zu 15% höhere Genauigkeit haben als das RF-Basismodell. Das SA-GRU-Modell hat darüber hinaus noch einen weiteren Vorteil: Die Integrierung der SA-Ebene in diesem neuronalen Netz erlaubt es, die Struktur des trainierten Modells zu interpretieren und diese mit den Interaktionen in der Lernumgebung in Verbindung zu stellen. So konnten die Autor_innen anhand der Verteilung der Gewichte des Netzes herausfinden, dass Simulationszustände (z.B. das Experimentieren mit einer roten Lösung und einem grünen Lichtstrahl) mehr Einfluss auf das erworbene konzeptuelle Verständnis hatten als Simulationsaktionen (z.B. die Änderung der Konzentration der Substanz oder der Breite des Behälters). Zudem zeigte sich, dass das Einstreuen von Reflektionspausen in bestimmten Momenten während der Aktivität ebenfalls Vorhersagekraft über das spätere konzeptuelle Verständnis der Lernenden hatte. Abschließend wurde auch analysiert, ob die Modelle für beide Geschlechter gleich gut funktionieren. Während für das SA-GRU-Modell keine Unterschiede gefunden wurden, zeigte das GRU-Modell ein leichter Bias für männliche Teilnehmer. Der berechnete AUC-Wert für sie war mit 0.78 leicht höher als der der Teilnehmerinnen (0.73). Für weiterführende Informationen zu diesem Forschungsprojekt seien interessierte Leser_innen auf den Originalartikel verwiesen (Cock et al., 2022).
Förderung von selbstgesteuertem Lernen
Relevanz von selbstgesteuertem Lernen
Die zunehmende Digitalisierung hat auch die Art und Weise verändert, wie in modernen Gesellschaften gelernt und gearbeitet wird. Um auf dem Arbeitsmarkt bestehen zu können, ist es für künftige Generationen mittlerweile unerlässlich, sich die Fähigkeit zum lebenslangen Lernen (engl. lifelong learning) anzueignen, um sich erfolgreich an die sich kontinuierlich verändernden Lebens- und Arbeitsbedingungen anpassen zu können (Field, 2000). Ein Kernkonzept ist dabei das selbstgesteuerte Lernen (engl. self-regulated learning, kurz SRL), welches die Prozesse beschreibt, mit denen Lernende selbstständig ihre Gedanken, Emotionen und Verhaltensweisen aktivieren und aufrechterhalten, um systematisch persönliche Lernziele zu erreichen (Zimmerman & Schunk, 2011). Der Erwerb von SRL-Kompetenzen ist besonders wichtig in Hinblick auf die vermehrten Lernangebote, welche nicht mehr traditionell im Klassenzimmer und unter Aufsicht einer Lehrperson stattfinden. Ein Beispiel dafür sind die zunehmend populärer werdenden Onlinekurse, die es den Lernenden erlauben, den Lernstoff nach ihrer eigenen Zeiteinteilung und in ihrem individuellen Lerntempo zu bearbeiten. Auf der einen Seite bieten solche Angebote mehr Flexibilität für die Lernenden, aber auf der anderen Seite tragen die Lernenden auch mehr Selbstverantwortung für ihren eigenen Lernerfolg. In ihrer Metaanalyse zeigten Broadbent und Poon (2015), dass es einen signifikanten Zusammenhang von akademischem Erfolg in Onlinekursen mit den folgenden fünf Unterkategorien von SRL gibt: Anstrengungsregulation (engl. effort regulation, Ausdauer beim Lernen), Zeitmanagement (time management, Fähigkeit, die Lernzeit zu planen), Metakognition (metacognition, Bewusstsein und Kontrolle der Gedanken), kritisches Denken (critical thinking, Fähigkeit zur sorgfältigen Prüfung von Lernmaterial) und das Suchen nach Hilfe (help-seeking, Einholen von Hilfe bei Bedarf).
SRL im umgedrehten Unterricht
SRL spielt des Weiteren auch im sogenannten umgedrehten Unterricht (engl. flipped classroom, kurz FC) eine tragende Rolle (Park & Kim, 2021; Shih, Liang & Tsai, 2019). In diesem immer populärer werdenden Lehr-Lern-Szenario wird die traditionelle Unterrichtsstruktur „umgedreht“, d.h., die Schüler_innen bearbeiten die Theorie und einen Teil der Übungen zunächst selbstständig zu Hause, bevor sie in den Unterricht kommen (Goedhart, Blignaut-van Westrhenen, Moser & Zweekhorst, 2019). Im Unterricht wird dann die Anwendung der Theorie vertieft, diskutiert und es werden Fragen besprochen (siehe Abbildung 3).
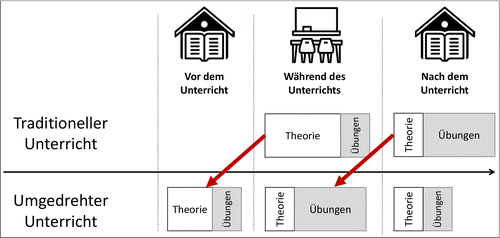
Auch wenn die vorbereitenden Aktivitäten in FC-Formaten wesentlich den Lernerfolg beeinflussen (Lee & Choi, 2019; Rahman et al., 2015; Yilmaz & Baydas, 2017), hat die bestehende Forschung gezeigt, dass Studierende diese oft nicht in vollem Umfang wahrnehmen. Dies geschieht unter anderem aufgrund von Mangel an Motivation, Zeit oder den notwendigen Fähigkeiten (Lai & Hwang, 2016; Mason, Shuman & Cook, 2013).
Beispiel: ML zur Analyse von selbstgesteuertem Lernen in FC-Kursen
Um zu veranschaulichen, wie ML zur Förderung von selbstgesteuertem Lernen eingesetzt werden kann, wird im Folgenden ein aktuelles Forschungsprojekt von Mejia-Domenzain, Marras, Giang und Käser (2022) vorgestellt. In ihrer Arbeit zeigen die Autor_innen, wie die Logdaten aus digitalen Lernumgebungen in den vorbereitenden Aktivitäten von FC-Kursen verwendet werden können, um Lernprofile in Hinblick auf selbstgesteuertes Lernen zu finden.
Analysierte FC-Kurse
In der Arbeit von Mejia-Domenzain et al. (2022) wurden die Logdaten aus drei Universitätsvorlesungen verwendet. Beim ersten Kurs handelt es sich um die Bachelorvorlesung Lineare Algebra (LA), welche von 292 Studierenden (29% weiblich) besucht wurde. Die Logdaten umfassen die Interaktionen der Studierenden mit dem Online-Videomaterial und den Onlinequiz der Vorlesung. Der zweite Kurs ist die Mastervorlesung Funktionelles Programmieren (FP), welche von 216 Studierenden (20% weiblich) besucht wurde. In diesem Fall umfassen die Logdaten nur die Interaktionen der Studierenden mit dem Videomaterial. Das gleiche gilt auch für den dritten Kurs Parallelismus und Gleichzeitigkeit (PC), eine weitere Mastervorlesung, die von 147 Studierenden (14% weiblich) besucht wurde.
Methoden
Aus den rohen Logdaten extrahierten die Autor_innen zunächst verschiedene Indikatoren, die mit verschiedenen Dimensionen von SRL in Verbindung gebracht wurden (siehe Tabelle 1). Diese Indikatoren wurden dann als Basis für eine ML-Methode verwendet, die sich spektrales Clustering (engl. spectral clustering; vgl. Ng, Jordan & Weiss, 2002) nennt. Durch diese Clusteranalyse konnten die Autor_innen für jeden Kurs verschiedene Lernprofile finden. Jedes Lernprofil ist dabei durch verschiedene Verhaltensweisen in Hinblick auf die untersuchten SRL-Dimensionen charakterisiert. Um die Lernerfolge der unterschiedlichen Profile zu vergleichen, wurden dann die Verteilungen der Kursnoten (1 = schlechteste und 6 = beste Note) aller Studierenden für jedes Profil untersucht.
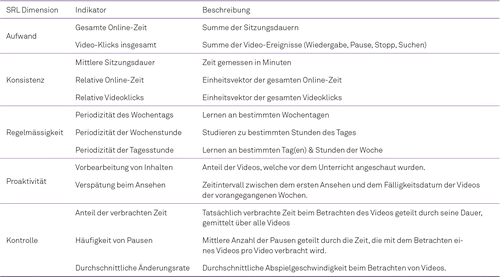
Ergebnisse
Die Ergebnisse zeigten, dass Studierende durchaus unterschiedliche Herangehensweisen in Bezug auf die vorbereitenden Aktivitäten von FC-Kursen haben. Mejia-Domenzain et al. (2022) fanden zehn verschiedene Lernprofile mit unterschiedlichen Charakteristiken in Bezug auf die ausgewählten SRL-Dimensionen. Während einige Profile einzigartig für den jeweiligen Kurs waren, gab es auch einige, welche man in zwei oder sogar allen drei Kursen wiederfinden konnte. Weiterhin analysierten die Autor_innen, wie sich die Verhaltensweisen der Lernprofile auf den Lernerfolg auswirkten. Die Analysen zeigten, dass es einen starken Zusammenhang zwischen der Zusammengehörigkeit zu einem Lernprofil und der erhaltenen Kursnote gab. Unter Anwendung des nichtparametrischen Kruskal-Wallis-Test zeigte sich, dass bestimmte Profile signifikant bessere Kursnoten erhielten, während andere vergleichsweise schlechter abschnitten. Mehr Details zu diesen Analysen finden sich im Originalartikel (Mejia-Domenzain et al., 2022).
Chatbots für Argumentationstraining
Chatbots für interaktive Lehr-Lern-Szenarien
Chatbots sind interaktive dialogbasierte Systeme, die es den Nutzer_innen ermöglichen, in natürlicher Sprache mit Computern zu kommunizieren. Modernere Systeme basieren dabei auch auf Algorithmen und Konzepten des maschinellen Lernens und der Verarbeitung natürlicher Sprache (engl. natural language processing; vgl. Bird, Klein & Loper, 2009). Durch das Zusammenspiel von dialogbasierter Interaktion und Möglichkeiten der adaptiven Anpassung an Nutzereingaben haben sich Chatbots zu einer zusätzlichen Klasse effektiver interaktiver Lernwerkzeuge entwickelt. Eingebettet in Lehr-Lern-Szenarien kann mit Chatbots interaktives Lernen skalierend und wirksam unterstützt werden. Dabei haben sich Chatbots nicht nur bei der Unterstützung niederer Lernziele bewiesen (z.B. Wissen wiedergeben; Ruan et al., 2019), sondern wurden in der Vergangenheit auch erfolgreich eingesetzt, um Lernende beim Trainieren metakognitiver Kompetenzen wie Argumentationsfähigkeiten adaptiv zu unterstützen (Wambsganss, Küng, Söllner & Leimeister, 2021). Des Weiteren werden Chatbots auch genutzt, um Lernende oder Lehrende indirekt im Lehr-Lern-Prozess zu unterstützen, bspw. durch die Durchführung von dialogbasierten Kursevaluationen (Xiao et al., 2020) oder das Beantworten häufiger Fragen zur Kurs- und Lernorganisation (Smutny & Schreiberova, 2020). Im Folgenden wird ein kurzer Überblick über Chatbots sowie deren Gestaltungsdimension beim Einsatz als Lernunterstützungswerkzeug aufgezeigt. Anschließend werden ein System aus der jüngsten Forschung von Wambsganss et al. (2021) und die begleiteten Studienergebnisse exemplarisch vorgestellt.
Dialogbasierte Interaktion
Chatbots basieren in der Regel auf einer Reihe definierter Sequenzen, wodurch eine bestimmte Nutzerkonversation modelliert wird. Die festgelegten Sprachsequenzen werden in einer Datenbank als vordefinierte Antworten gespeichert. Hierbei wird auch definiert, bei welcher Nutzereingabe (bspw. Schlagwörter) welche Antwortsequenz vom System ausgegeben wird. Durch die geschickte Gestaltung dieser Antwortsequenzen entsteht bei den Nutzer_innen dadurch der Eindruck einer intelligenten Konversation mit dem System – ähnlich wie bei einem Dialog („Chat“) mit einem echten Menschen. Im Allgemeinen werden Chatbots häufig als rein regelbasierte Systeme (ähnlich wie Automaten) implementiert, was aber den Raum für mögliche Interaktionen außerhalb der vordefinierten Sequenzen stark einschränkt. Die zusätzliche Integration von ML-basierten Methoden ermöglicht komplexere Interaktionen, da z.B. verschiedene Formulierungen einer Aussage vom Chatbot verstanden werden können und dieser mit zunehmenden Eingabedaten dazulernen kann. Abbildung 4 zeigt eine Übersicht über die grundlegende Architektur eines dialogbasierten Lehr-Lern-Szenarios mit einem Chatbotserver. Neuere Systeme basieren auch auf generativen Modellen, jedoch sind diese in den Bildungswissenschaften aufgrund der nicht kontrollierbaren Sequenzabfolge zurzeit noch wenig erforscht (Winkler & Söllner, 2018). Die Grundidee, dialogbasierte Software zu gestalten, welche in natürlicher Sprache mit den Nutzer_innen interagieren, entstand bereits in den 1960er-Jahren (Hobert & Meyer von Wolff, 2019).
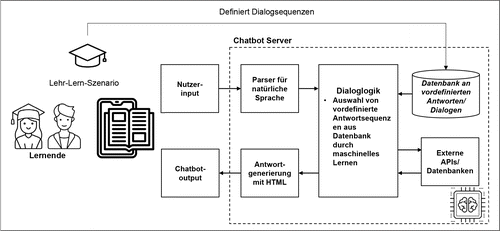
ELIZA war der erste Chatbot und wurde 1966 von Jo seph Weizenbaum mit dem Ziel entwickelt, den Dialog mit einer Psychotherapeutin oder einem Psychotherapeuten zu imitieren (Shum, He & Li 2018). Heutzutage nimmt der Einsatz dieser und andere Chatbots eine wichtige Rolle in vielen Bereichen unseres täglichen Lebens ein. Dialogbasierte Systeme wie Apples Siri, Amazons Alexa oder Googles Sprachassistent ermöglichen Nutzer_innen in natürlicher Sprache mit Computern zu kommunizieren und so Befehle auszuführen. Klassische textbasierte Chatbots werden bereits in verschiedenen Forschungsfeldern wie der Finanzberatung (Morana, Gnewuch, Jung & Granig, 2020), der Telemedizin (Kowatsch et al., 2017), der Dienstleistungsbranche (Gnewuch, Morana & Maedche, 2017) oder der Datenanalyse (Rietz, Benke & Maedche, 2019) als Systeme zur Verbesserung der Nutzerinteraktion erfolgreich eingesetzt.
Chatbots in den Bildungswissenschaften
In den Bildungswissenschaften haben Anderson, Corbett, Koedinger und Pelletier (1995) den Begriff „Kognitive Tutoren“ definiert und damit das Forschungsfeld von intelligenten Lernsystemen neu strukturiert. Der Begriff grenzt sich dabei vor allem durch die Integration von adaptiven Eigenschaften (mit kognitiven Elementen) von anderen Lernsystemen ab. Als Unterklasse dieser intelligenten Lernsysteme reihen sich Chatbots damit in eine prominente Reihe von adaptiven Lernsystemen ein. In der Vergangenheit wurden Chatbots in unterschiedlichste Lehr-Lern-Szenarien eingebettet und evaluiert. Beispielsweise hat Kim (2018) einen Chatbot entwickelt, der das Gespräch mit einem Lernpartner modelliert und dadurch Lernenden die Möglichkeit gibt, sich interaktiv auszutauschen. Andere Autor_innen haben Chatbots entwickelt, um Lernenden während des Lernprozesses als Tutor zur Verfügung zu stehen oder Feedback zu Textaufgaben zu geben (Winkler & Söllner, 2018). Neuere Studien über Chatbots haben gezeigt, dass diese in der Lage sind, nicht nur den individuellen Bedürfnissen der Lernenden gerecht zu werden und ihre Motivation, Selbstwirksamkeit oder den Spaßfaktor beim Lernen zu steigern, sondern neben Faktenwissen auch höhere metakognitive Lernziele wie Problemlösungs- (Winkler, Söllner & Leimeister, 2021) oder Argumentationsfähigkeiten zu fördern (Wambsganss et al., 2021).
Gestaltungsmerkmale von Chatbots in den Bildungswissenschaften
Um das Forschungsfeld besser zu ordnen und Anwender_innen in den Bildungswissenschaften einen möglichst umfassenden Überblick über den Gestaltungsspielraum von Chatbots zu geben, haben Weber, Wambsganss, Rüttimann und Söllner (2021) eine Taxonomie der Gestaltungsmerkmale von Chatbots für den Einsatz in der Bildung erstellt. In einer systematischen Analyse und mit einem deduktiven Forschungsansatz nach Nickerson, Varshney und Muntermann (2013) haben die Autoren 92 empirische Studien über den Einsatz von Chatbots in der Bildung analysiert. Als Ergebnisse wurden zehn Gestaltungsdimensionen mit zahlreichen Merkmalen identifiziert. Diese fassen den aktuellen Stand der Literatur zusammen und sollen Anwender_innen einen Überblick über den Gestaltungsraum von Chatbots für den Einsatz in der Lehre geben. Die zehn Dimensionen sind nach den Bestandteilen eines soziotechnischen Systems strukturiert (Bostrom & Heinen, 1977). Dabei spielt als erste Komponente der Einsatz der zugrundeliegenden Technologie eine zentrale Rolle. Nach der Taxonomie von Weber et al. (2021) kann beim Einsatz der Technologie unterschieden werden zwischen den Gestaltungsdimensionen „Chatbot-Gestaltung“ (bspw. Personifizierung des Chatbots als Lehrperson), „Back-End“ (regelbasiert oder lernbasiert), „Interaktionsin- und output“ (bspw. Text oder Sprache) und „Chatbot-Einbettung“ (bspw. Einbettung in vorhandene soziale Medien wie Facebook Messenger). Zusätzlich zu der eigentlichen Technologie spielen in ihrer Taxonomie aber auch andere Elemente eine zentrale Rolle. Diese umfassen die gewünschte Rolle des Chatbots beim Lernen (Funktion als Tutor_in oder Lernpartner_in), die Lernzielebene (bspw. Faktenwissen) sowie die zu erreichende Zielgruppe der Endnutzer_innen. So ist es z.B. wichtig, zu unterscheiden, ob man einen Chatbot für Lernende im Kindergartenalter oder für Studierende an Universitäten entwickelt.
Als Letztes spielt bei der Gestaltung eines dialogbasierten Lernsystems die Berücksichtigung und Einbettung der Technologie in ein spezifisches Lehr-Lern-Szenario eine wichtige Rolle. Das pädagogische Anwendungssetting und bestimmte Facetten im didaktischen Aufbau des Lernprozesses sollten als Gestaltungsparameter berücksichtigt und adaptiert werden. Mehr Information über die Gestaltungsmerkmale sowie Erkenntnisse über den Einfluss von verschiedenen Kombinationen der Gestaltungsmerkmale und deren Auswirkung auf subjektive und objektive Messungen finden sich in Weber et al. (2021).
Beispiel: Der ArgueTutor-Chatbot
Um einen tieferen Einblick in die Konzeption und Gestaltung von dialogbasierten Lernsystemen zu geben, werden im Folgenden der Chatbot ArgueTutor von Wambsganss et al. (2021) vorgestellt und die dazugehörigen Forschungsergebnisse aufgezeigt. ArgueTutor ist ein Chatbot, der Lernende beim Schreiben argumentativer Texte unterstützt, und hat zum Ziel, deren Argumentationsfähigkeiten zu fördern. Die Forschungsidee von ArgueTutor war es, zu untersuchen, ob man Lernende bei argumentativen Schreibübungen mit adaptivem dialogbasiertem Feedback skalierend dabei helfen kann, ihre Argumentationsfähigkeiten zu verbessern.
Gestaltung von ArgueTutor
Um diese Hypothese zu testen, entwickelten die Autoren ein neuartiges dialogbasiertes Lernsystem namens ArgueTutor (kurz für Argumentationstutor). Aufbauend auf einem theoriebegleiteten Ansatz und Anforderungen abgeleitet aus zwölf Interviews mit Lernenden, wurden zunächst verschiedene Protopyen für die Konzeption des Lernwerkzeugs entwickelt. Nach weiterem Nutzerfeedback wurde schließlich eine finale Version von ArgueTutor anhand von fünf Gestaltungsprinzipien konzipiert. Mehr zu dem Entwicklungsprozess, der Architektur und den fünf Gestaltungsprinzipien findet man in Wambsganss et al. (2021). Um das dialogbasierte Lernwerkzeug zu entwickeln, haben die Autoren die Dialoglogik von ArgueTutor auf Grundlage von genau definierten Lehrer-Schüler-Konversationen und daraus abgeleiteten Dialogsequenzen trainiert. Das adaptive Argumentationsfeedback von ArgueTutor basiert auf einem Argumentation Mining Model, das die individuelle Argumentationsqualität von Texten anhand des von Toulmin (2003) entwickelten Modells bewertet.
Methoden
Um die Auswirkungen von ArgueTutor auf die Argumentationsfähigkeiten der Studierenden ebenso wie auf deren Wahrnehmung während des Lernprozesses zu ermitteln, wurde ein Laborexperiment mit 55 Studierenden durchgeführt. Die Teilnehmer_innen wurden randomisiert einer der zwei verschiedenen experimentellen Gruppen zugeteilt. Gruppe 1 (G1) nutzte das entwickelte dialogbasierte Lernsystem ArgueTutor mit adaptivem Feedback (siehe Abbildung 5). Teilnehmer_innen der Kontrollgruppe (KG) nutzten einen Skriptingansatz für die gleiche argumentative Aufgabe, welcher den Lernenden statisches Argumentationsfeedback auf der Grundlage der Argumentationstheorie nach Toulmin (2003) lieferte. In einem Prätest wurde die Randomisierung kontrolliert sowie das Konstrukt der passiven argumentativen Kompetenz nach Flender, Christmann und Groeben (1999) gemessen, um sicherzustellen, dass sich die passive argumentative Kompetenz der Teilnehmenden nicht signifikant unterscheidet. Im Posttest wurden verschiedene Konstrukte zur Technologieakzeptanz sowie die formelle Qualität der Argumentation nach Weinberger und Fischer (2006) gemessen. Mehr zu den Messungen, der Demografie der Teilnehmer_innen und den exakten Konstrukten finden sich im Originalbeitrag von Wambsganss et al. (2021).
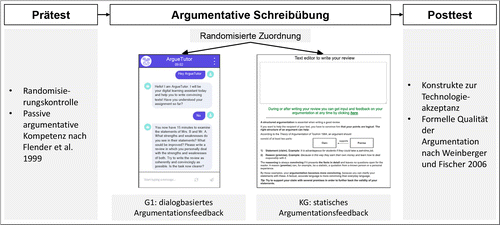
Ergebnisse
Die Analysen zeigten, dass Studierende, die ArgueTutor verwendeten, überzeugendere Texte mit einer höheren Qualität der formalen Argumentation schrieben als Studierende, die das nicht dialogbasierte Lernwerkzeug nutzten. Die durchschnittliche Anzahl der Argumente in den Texten der Teilnehmer_innen, die ArgueTutor für die Schreibübung verwendeten, betrug 3.56 (SD = 1.81). Für die Texte der Teilnehmer_innen, die das alternative statische Lernwerkzeug verwendeten, wurden durchschnittlich 2.64 Argumente (SD = 1.21) gezählt. Ein zweiseitiger t-Test bestätigte, dass Teilnehmer_innen der Gruppe 1 ihre Texte mit einer statistisch signifikant höheren Qualität der formalen Argumentation schrieben: t-Wert = 2.1738 und p-Wert = .03459 (p < .05). Um die Wahrnehmung der Studierenden während der Schreibübung zu bewerten, berechneten die Autoren die Mittelwerte der wahrgenommenen Benutzerfreundlichkeit und der Freude im Lernprozess. Die wahrgenommene Benutzerfreundlichkeit von ArgueTutor wurde auf einer fünfstufigen Likert-Skala (mit 1 = niedrig und 5 = hoch) mit einem Mittelwert von 3.73 (SD = 0.64) bewertet und der Mittelwert der wahrgenommenen Freude von ArgueTutor lag bei 3.41 (SD = 0.89, gleiche Likert-Skala). Diese Werte sind signifikant besser als die Ergebnisse des alternativen Ansatzes, für den eine mittlere wahrgenommene Benutzerfreundlichkeit von 3.45 (SD = 0.69) und für die wahrgenommene Freude am Lernen ein Mittelwert von 3.00 (SD = 0.88) ermittelt wurden. Mehr Information zu ArgueTutor findet man in Wambsganss et al. (2021).
Diskussion
In dieser Übersichtsarbeit wurden einige ausgewählte Anwendungsmöglichkeiten von maschinellem Lernen zur Förderung von höheren Lernkompetenzen vorgestellt. Die einschneidenden Veränderungen, die moderne Gesellschaften durch die Digitalisierung erfahren haben, machen es unerlässlich, dass auch neu überdacht werden muss, welche Kompetenzen heutigen und künftigen Generationen als Rüstzeug für die Lern- und Arbeitswelt mitgegeben werden sollten. Die Kompetenzen des 21. Jahrhunderts (Van Laar et al., 2017) gehen weit über das Abrufen von statischem Wissen hinaus – stattdessen wird von der heutigen und künftigen Generation von Arbeitskräften erwartet, sich den konstant verändernden Umgebungen anzupassen (Littlejohn & Pammer-Schindler, 2022). Das Lernen und Lehren der damit verbundenen höheren Kompetenzen ist naturgemäß erheblich komplexer. Forschungs- und Problemlösungskompetenzen, selbstgesteuerte Lernkompetenz und Argumentationsfähigkeiten lassen sich in der Tat nur schwierig mit dem Textbuch erlernen und üben. Intelligente digitale Lernumgebungen stellen in diesem Kontext eine interessante Möglichkeit dar, solche Kompetenzen zu erlernen und zu üben. Die bestehende Forschung hat jedoch auch gezeigt, dass viele Lernende oftmals Schwierigkeiten haben, solche Lernumgebungen effektiv zu verwenden (Alfieri, Brooks, Aldrich & Tenenbaum 2011; Kirschner, Sweller & Clark, 2006; Mayer, 2004). Die Kombination von digitalen Lernumgebungen mit Methoden des maschinellen Lernens könnte hier Abhilfe schaffen, indem die Lernerfahrungen sich adaptiv an die Motivation, das Interesse und das Niveau der Lernenden anpassen.
Relevanz für die Praxis
Die in diesem Artikel vorgestellten Anwendungsbeispiele aus der jüngsten Forschung zeigen, dass es tatsächlich ein enormes Potenzial für solche ML-basierten Anwendungen in der Bildung gibt. Wie in der Arbeit von Cock et al. (2022) gezeigt, ist es bereits auf dem heutigen Stand der Technologie möglich, anhand der digitalen Logdaten von Lernenden mit guter Genauigkeit vorherzusagen, welcher Lernerfolg zu erwarten ist. Dies öffnet die Türen für personalisierte Interventionen, welche es erlauben, sowohl über- als auch unterforderte Schüler_innen zielgerichtet zu unterstützen. Die Erkenntnisse, die von ML-Modellen zur Verfügung gestellt werden, können dabei von Lehrpersonen genutzt werden, um den Unterricht nach den wirklichen Bedürfnissen der Lernenden zu gestalten. Wie in der Arbeit von Wambsganss et al. (2021) gezeigt, können durch ML auch völlig automatische Lernsysteme wie Chatbots entstehen, welche Lernenden neue Umgebungen eröffnen, in denen sie vollständig autonom lernen können. Das Beispiel von Mejia-Domenzain et al. (2022) hat darüber hinaus auch gezeigt, dass ML verwendet werden kann, um Einblicke in Lernprofile zu erhalten, welche für Lehrpersonen sonst völlig unentdeckt bleiben würden. Ein wichtiger Aspekt, der in diesem Artikel aufgegriffen wurde, ist die Interpretierbarkeit von ML-Modellen. Die bestehende Forschung hat sich dafür ausgesprochen, dass die Anwendung von ML in der Bildung nur dann einen positiven Einfluss auf den Lernerfolg von Lernenden hat, wenn die Modelle eine gute Genauigkeit und Interpretierbarkeit haben (Conati, Proayska-Pomsta & Mavrikis, 2018). In den Arbeiten von Mejia-Domenzain et al. (2022) und Cock et al. (2022) hat sich gezeigt, dass es schon heute geeignete ML-Modelle gibt, welche beide Faktoren ausreichend gut sicherstellen können. Die Ergebnisse dieser Modelle lassen sich von Forschenden und Lehrenden gleichermaßen gut und einfach interpretieren, was einen wichtigen Grundstein für weiterführende Verbesserungen solcher Systeme bilden kann.
Limitationen
Auch wenn diese neuesten Ergebnisse vielversprechend sind, so sollte dennoch angemerkt werden, dass es noch weiterführende Forschung braucht, um ML-basierte Lernsysteme wirklich lernwirksam einzusetzen. Die meisten der hier vorgestellten Ergebnisse stammen aus Forschungsprojekten, welche die Anwendbarkeit solcher Systeme in einzelnen Kontexten und mit teils großen Einschränkungen ausgewertet haben. Auch wurden noch keine Langzeitstudien zum Einsatz solcher ML-basierten Lernsysteme gemacht, die aber dringend nötig sind, um den wirklichen Einfluss auf den Lernerfolg zu messen. Ebenfalls sollte erwähnt werden, dass die Ergebnisse, die in dieser Übersichtsarbeit vorgestellt wurden, allein auf den Logdaten aus den digitalen Lernumgebungen basieren. Auch wenn diese interessante Einblicke in die individuellen Lernprozesse geben können, sollte beachtet werden, dass sie nur eine Facette des Lernens widerspiegeln. Das Erlernen von (besonders höheren) Kompetenzen ist ein komplexer Vorgang, welcher zwingend umfangreichere Ansätze braucht, um die Gesamtheit dieser Komplexität nachzuvollziehen. Dabei geht es nicht nur um die Verwendung von verschiedenen Technologien zum Sammeln von möglichst umfangreichen Datensätzen. Viel wichtiger wird es sein, dass ML-basierte Methoden pädagogisch sinnvoll in das soziotechnische Gesamtsystem eingebettet werden, um Lernförderlichkeit zu garantieren. Die Wichtigkeit der sinnvollen Einbettung von Technologien in das Bildungswesen wurde bereits in existierenden Arbeiten hervorgehoben (Lauwers, 2010). Die erfolgreiche Anwendung von ML-basierten Methoden wird stark davon abhängen, wie gut diese auf das Zusammenspiel mit Lernaktivitäten, Lernzielen, Lernkontrollen und Kompetenzmodellen abgestimmt sind. In diesem Zusammenhang wird Pädagog_innen eine umfassende Rolle in der Gestaltung solcher Systeme zukommen, da es im Endeffekt nicht nur darum geht, möglichst viele Daten als Eingabe für ML-Modelle zu verwenden. Vielmehr geht es darum, zu definieren, was die richtigen Daten und Modelle sind, um ML-Systeme wirklich sinnvoll einzusetzen. Abschließend bleibt anzumerken, dass – wie bei so vielen ML-Anwendungen – ein besonderer Fokus auf die Fairness solcher Systeme gelegt werden muss. Wie im Beispiel der Arbeit von Cock et al. (2022) gezeigt, besteht in vielen der verwendeten Modelle die implizite Gefahr, dass diese zu sehr auf die Mehrheitsgruppe angepasst sind. Forschende müssen sich dieser Gefahr bewusst sein, um nicht unbewusst Lernsysteme zu entwickeln, welche potenziell den Lernerfolg von einzelnen Schüler_innen beeinträchtigen könnten.

Literatur
(2022). Knowledge tracing: A survey. arXiv preprint arXiv:2201.06953 .
(2011). Does discovery-based instruction enhance learning? Journal of Educational Psychology , 103 , 1–18.
(1995). Cognitive tutors: Lessons learned. Journal of the Learning Sciences , 4 , 167–207.
(2014). A multimedia adaptive tutoring system for mathematics that addresses cognition, metacognition and affect. International Journal of Artificial Intelligence in Education , 24 , 387–426.
(2016). Towards general models of effective science inquiry in virtual performance assessments. Journal of Computer Assisted Learning , 32 , 267–280.
(2017). Adaptive feedback in computer-based learning environments: A review. Adaptive Behavior , 25 , 217–234.
(2009). Natural language processing with Python: Analyzing text with the natural language toolkit . Sebastopol: O›Reilly Media, Inc.
(1977). Mis problems and failures: A socio-technical perspective. Part I: The causes. MIS Quarterly , 1 (3), 17–32.
(2015). Self-regulated learning strategies & academic achievement in online higher education learning environments: A systematic review. Internet and Higher Education , 27 , 1–13.
(2015). Educational Data Mining and Learning Analytics: Differences, similarities, and time evolution. International Journal of Educational Technology in Higher Education , 12 , 98–112.
(2021). Early prediction of conceptual understanding in interactive simulations. In Proceedings of the 14th International Conference on Educational Data Mining , 161–171.
(2022). Generalisable methods for early prediction in interactive simulations for education. In Proceedings of the 15th International Conference on Educational Data Mining . Available from https://educationaldatamining.org/EDM2022/proceedings/2022.EDM-long-papers.16/
(2018). AI in education needs interpretable machine learning: Lessons from open learner modelling. arXiv preprint arXiv:1807.00154 .
(2019). Detecting mistakes in CPR training with multimodal data and neural networks. Sensors , 19 (14), 3099.
(2018). Recommender systems for large-scale social networks: A review of challenges and solutions. Future Generation Computer Systems , 78 , 413–418.
(2000). Lifelong learning and the new educational order. London: Trentham Books, Ltd.
(1999). Entwicklung und erste Validierung einer Skala zur Erfassung der passiven argumentativ-rhetorischen Kompetenz. Zeitschrift fur Differentielle und Diagnostische Psychologie , 20 , 309–325.
(2013). Constructivism: Theory, perspectives, and practice . New York: Teachers College Press.
(2015). Making sense of students' actions in an open-ended virtual laboratory environment. Journal of Chemical Education , 92 , 610–616.
(2019). Estimation of energy consumption in machine learning. Journal of Parallel and Distributed Computing , 134 , 75–88.
(2017). Towards designing cooperative and social conversational agents for customer service. In Proceedings of the International Conference on Information Systems (ICIS) 2017 .
(2019). The flipped classroom: Supporting a diverse group of students in their learning. Learning Environments Research , 22 , 297–310.
(2014). Domain-general problem-solving skills and education in the 21st century. Educational Research Review , 13 , 74–83.
(2007). Errors and intelligence in computer-assisted language learning: Parsers and pedagogues . New York: Routledge.
(2019). Say hello to your new automated tutor – a structured literature review on pedagogical conversational agents. In Tagungsband 14. Internationale Tagung Wirtschaftsinformatik (WI 2019) .
(2019). Superimposed skilled performance in a virtual mirror improves motor performance and cognitive representation of a full body motor action. Frontiers in Robotics and AI , 6 , 43.
(2017). Modeling exploration strategies to predict student performance within a learning environment and beyond. In Proceedings of the Seventh International Learning Analytics & Knowledge Conference , 31–40.
(2018). A study on chatbots for developing Korean college students' English listening and reading skills. Journal of Digital Convergence , 16 (8), 19–26.
(2006). Why unguided learning does not work: An analysis of the failure of discovery learning, problem-based learning, experiential learning and inquiry-based learning. Educational Psychologist , 41 , 75–86.
(2017). Text-based healthcare chatbots supporting patient and health professional teams: Preliminary results of a randomized controlled trial on childhood obesity. In Proceedings of Persuasive Embodied Agents for Behavior Change 2017.
(2016). A self-regulated flipped classroom approach to improving students' learning performance in a mathematics course. Computers & Education , 100 , 126–140.
(Eds.). (2012). Theoretical foundations of learning environments . London: Routledge.
(2010). Aligning capabilities of interactive educational tools to learner goals . PhD Thesis, Carnegie Mellon University.
(2019). Rethinking the flipped learning pre-class: Its influence on the success of flipped learning and related factors. British Journal of Educational Technology , 50 , 934–945.
(2022).
Technologies for professional learning (pp. 321 – 346). In D. Gijbels C. Harteis E. Kyndt (Eds.), Research approaches on workplace learning . Cham: Springer.(2011).
Recommender systems in technology enhanced learning (pp. 387 – 415). In F. Ricci L. Rokach B. Shapira P. B. Kantor (Eds.), Recommender systems handbook . New York: Springer.(2013). Comparing the effectiveness of an inverted classroom to a traditional classroom in an upper-division engineering course. IEEE Transactions on Education , 56 , 430–435.
(2004). Should there be a three-strikes rule against pure discovery learning? American Psychologist , 59 , 14–19.
(2021). A survey on bias and fairness in machine learning. ACM Computing Surveys (CSUR) , 54 (6), 1–35.
(2022). Identifying and comparing multi-dimensional student profiles across flipped classrooms (pp. 90 – 102). In International Conference on Artificial Intelligence in Education . Cham: Springer.
(2020). The effect of anthropomorphism on investment decision-making with robo-advisor chatbots. In Proceedings of European Conference on Information Systems (ECIS) 2020 .
(2001). On spectral clustering: Analysis and an algorithm. Advances in Neural Information Processing Systems , 14 , 849–856.
(2013). A method for taxonomy development and its application in information systems. European Journal of Information Systems , 22 , 336–359.
(2020). A systematic review on the impacts of game-based learning on argumentation skills. Entertainment Computing , 35 , 100369.
(2012). Guru: A computer tutor that models expert human tutors (pp. 256 – 261 ). In International Conference on Intelligent Tutoring Systems . Berlin: Springer.
(2021). University students' self-regulation, engagement and performance in flipped learning. European Journal of Training and Development , 46 (1–2), 22–40.
(2015). Phases of inquiry-based learning: Definitions and the inquiry cycle. Educational Research Review , 14 , 47–61.
(2017). Bayesian knowledge tracing, logistic models, and beyond: An overview of learner modeling techniques. User Modeling and User-Adapted Interaction , 27 , 313–350.
(2017). Identifying productive inquiry in virtual labs using sequence mining (pp. 287 – 298 ). In International Conference on Artificial Intelligence in Education . Cham: Springer.
(2019). A comparison of the quality of data-driven programming hint generation algorithms. International Journal of Artificial Intelligence in Education , 29 , 368–395.
(2015). Significance of preparedness in flipped classroom. Advanced Science Letters , 21 , 3388–3390.
(2019). The impact of anthropomorphic and functional chatbot design features in enterprise collaboration systems on user acceptance. In Tagungsband 14. Internationale Tagung Wirtschaftsinformatik (WI 2019) .
(2019). Quizbot: A dialogue-based adaptive learning system for factual knowledge. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems , 1–13.
(2006). Machine learning for detection and diagnosis of disease. Annual Review of Biomedical Engineering , 8 , 537–565.
(2018). Current challenges and visions in music recommender systems research. International Journal of Multimedia Information Retrieval , 7 , 95–116.
(2019). Exploring the role of university students' online self-regulated learning in the flipped classroom: A structural equation model. Interactive Learning Environments , 27 , 1192–1206.
(2018). From Eliza to XiaoIce: Challenges and opportunities with social chatbots. Frontiers of Information Technology & Electronic Engineering , 19 , 10–26.
(2020). Chatbots for learning: A review of educational chatbots for the facebook messenger. Computers & Education , 151 , 103862.
(2019). The facts of fake news: A research review. Sociology Compass , 13 , 12724.
(2020). Sustaining lifelong learning: A self-regulated learning (SRL) approach. Discourse and Communication for Sustainable Education , 11 , 5–15.
(2020). Identifying patterns of students' performance on simulated inquiry tasks using PISA 2015 log-file data. Journal of Research in Science Teaching , 57 , 1400–1429.
(2003). The uses of argument . Cambridge: Cambridge University Press.
(2017). The relation between 21st-century skills and digital skills: A systematic literature review. Computers in Human Behavior , 72 , 577–588.
(2010). 21st century skills. Discussienota . Zoetermeer, NL: Kennisnet.
(2021). Arguetutor: An adaptive dialog-based learning system for argumentation skills. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , 1–13.
(2021). Pedagogical agents for interactive learning: A taxonomy of conversational agents in education. In Forty-Second International Conference on Information Systems, Austin .
(2007). A survey of e-commerce recommender systems. In 2007 International Conference on Service Systems and Service Management , 1–5.
(2006). A framework to analyze argumentative knowledge construction in computer-supported collaborative learning. Computers & Education , 46 , 71–95.
(2018). Maschinelles Lernen. HMD Praxis der Wirtschaftsinformatik , 55 , 366–382.
(2008). Phet: Simulations that enhance learning. Science , 322 (5902), 682–683.
(2018). Unleashing the potential of chatbots in education: A state-of-the-art analysis. In Academy of Management Annual Meeting (AOM) .
(2021). Enhancing problem-solving skills with smart personal assistant technology. Computers & Education , 165 , 104148.
(2020). Tell me about yourself: Using an AI-powered chatbot to conduct conversational surveys with open-ended questions. ACM Transactions on Computer-Human Interaction (TOCHI) , 27 (3), 1–37.
(2017). An examination of undergraduates' metacognitive strategies in pre-class asynchronous activity in a flipped classroom. Educational Technology Research and Development , 65 , 1547–1567.
(2013). Individualized bayesian knowledge tracing models (pp. 171 – 180). In 16th International Conference on Artificial Intelligence in Education . Cham: Springer.
(2019). A review of machine learning and IoT in smart transportation. Future Internet , 11 (4), 94.
(2011).
Self-regulated learning and performance: An introduction and an overview (pp. 1 – 12). In D. H. Schunk B. J. Zimmerman (Eds.), Handbook of self-regulation of learning and performance . New York: Routledge.

