

Why Psychological Assessment Needs to Start Worrying About Model Fit
Anything Wrong With Model Fit?
Imagine, you just received the cleaned and ready-to-go data set of a scale development project that is dear to your heart. Excitedly, you run a confirmatory factor analysis (CFA), for the newly developed scale to see whether it follows the hypothesized factorial structure, say, a unidimensional structure. Good news right away: the fit for the factorial structure is RMSEA = .02, CFI = .98, and SRMR = .03. You conclude, probably just as 99% of other researchers working in assessment would, that you found support for the unidimensional structure.
Maybe – maybe not! Why not, you wonder?
Short and straightforward answer: Because goodness of fit (GoF) in structural equation modeling (SEM) as indicated by fit indices depends on a number of factors and many of these factors (called nuisance parameters) are totally unrelated (!) to the actual degree of model misspecification. Examples of these nuisance parameters are sample size, size of factor loadings of the items, the number of items per latent variable, and so forth (cf. Breivik & Olsson, 2001; Chen, Curran, Bollen, Kirby, & Paxton, 2008; Fan & Sivo, 2007; Garrido, Abad, & Ponsoda, 2016; Heene, Hilbert, Draxler, Ziegler, & Bühner, 2011; Heene, Hilbert, Freudenthaler, & Bühner, 2012; McNeish, An, & Hancock, 2017; Saris, Satorra, & van der Veld, 2009; Yuan, 2005). Put differently, according to Saris, Satorra, and van der Veld cutoff-values for fit indices vary dramatically with the values of nuisance parameters that do not have any connection to the actual level of misspecification. Even worse and contrary to standard practice, there are no “golden rules” that are applicable across data and model constellations, not even for widely used fit indices such as RMSEA, CFI, or SRMR.
Wait a second, you may say. Isn’t there some seminal and highly cited work out there that has established standard cutoff-values? Hu and Bentler (1999) for instance. Yes and no. Yes, seminal and highly cited this work is (exceeding 42,000 according to Google Scholar in August 2017), but applicable as standard for various model types, ranging from unidimensional CFAs to complex SEMs involving many latent variables with a hypothesized complex causal interplay? No!
Although Hu and Bentler (1999) explicitly warned against an overgeneralization of their inferences because they were restricted to only those confirmatory factor analytic models Hu and Bentler specifically investigated, their suggested cutoff-values were rather mindlessly applied to all sorts of SEMs. Jackson, Gillaspy, and Purc-Stephenson (2009) pointed to the fact that almost 60% of studies explicitly used the suggested cutoff-values by Hu and Bentler but the authors “…did not find evidence that warnings about strict adherence to Hu and Bentler’s suggestions were being heeded” (p. 18). This is, in fact, troublesome as the general conclusion from many simulation studies is that the sensitivity of the suggested cutoff-values to detect model misspecifications is disappointingly low for models that are more complex than those used in Hu and Bentler’s simulation study.
The upshot of these simulation studies is that the strong reliance on the cutoff-values by Hu and Bentler (1999) results in a high failure to reject false and often grossly misspecified models. This, in turn, raises questions about the claimed validity of published SEMs and the theories they are based on. Just the other way around, the rate of wrong rejections of correctly specified models can also be severely inflated by these cutoff-values. Nevertheless, failure to reject errors is more serious in model testing as they would erroneously support a theoretical model, whereas a wrong rejection error would result in not supporting a theory, but at the end of the day relying on the established cutoff-values will lead to both: too conservative and too liberal decisions.
Unfortunately, this highly relevant topic has escaped many researchers interested in assessment and has yet to penetrate actual practice. The aims of this editorial are (1) to give some insights into the methodology (i.e., simulation studies) that is used to create knowledge on the behavior of GoF indices; (2) to provide a brief overview of what the gist of this research is; (3) to look ahead and discuss what authors can do about this when writing up their findings. We will not, however, discuss the statistical rationales of the various GoF indices since this is beyond the scope of this editorial. Interested readers should consult, for example, Mulaik (2009) for a detailed account.
The Principle Behind Simulation Studies on Model Fit
Let us first give a conceptual explanation of what a simulation study on model fit assessment actually does to gain a basic understanding of the matter and to illustrate what we know from such studies.
For instance, to investigate the performance of the commonly applied GoF statistic RMSEA, CFI, and SRMR and their suggested cutoff-values of RMSEA < .06, CFI > .95, and SRMR < .08 in a simulation study, we first define a true population model by specifying the number of latent and observed variables and all model parameter values (e.g., variances of exogenous latent variables and observed, latent variable correlations, mean structure, values of factor loadings, etc.). We then construct a misspecified model by setting certain parameters such as loadings or path values to a value other than the actual population value. For instance, we could set cross loadings of some of the items to zero although they might be nonzero in the population, or, we could set a path coefficient between two latent variables to zero in the hypothesized model although it is nonzero in the population model. Alternatively, we could also specify an entirely different model structure by hypothesizing, for instance, a unidimensional latent variable in the misspecified model instead of the multidimensional structure as defined in the population model.
In any of the aforementioned cases of model misspecifications, we would then investigate whether the GoF, given a prespecified cutoff-value, would flag the misspecified model indeed as misfitting. This is done by following these steps: Sample data for a defined sample size (e.g., N = 200 as in the example below) are generated from the population model many times (usually ≥ 1,000) under a distributional model (e.g., multivariate normality). These sample data sets are then analyzed using the misspecified model and the GoFs are calculated for each sample. In the final step, the fraction of GoFs that yielded values worse than their suggested cutoff-values is calculated to determine the correct rejection rate.
The following example further illustrates the idea. Figure 1 depicts two true population models (twodimensional models) and a misspecified model (assuming unidimensionality of the items). Note that in population model A the factor correlation was set to .50, whereas model B shows one of .60. Thus, the degree of misspecification brought about by the unidimensional model is higher under data generated under model A than under model B. Nevertheless, it should still be obvious that two factors sharing 36% of the variance in the q = .60 condition can hardly be regarded as identical factors and that we are confronted with a grossly misspecified model even under this condition. Please note that the factor loadings we chose in the example are quite realistic, for instance when compared to those of the NEO Five-Factor Inventory (NEO-FFI; McCrae & Costa, 2004).
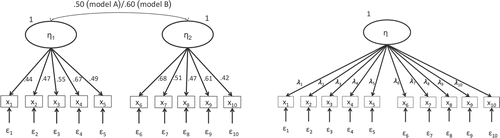
One thousand random sample data replications from multivariate normally distributed observed variables were generated from the true population model under each condition with N = 200 as the typical sample size in the social sciences according to Kline (2015) and Shah and Goldstein (2006). The R package simsem (Pornprasertmanit, Miller, & Schoemann, 2015) was used to carry out the simulation. Model parameters of the misspecified model were then estimated for each of these sample data using maximum likelihood estimation and correct rejection rates and descriptive statistics were then calculated for the suggested cutoff-values (Hu & Bentler, 1999) of the above-mentioned fit indices (the simulation codes can be downloaded from https://osf.io/sm9ha). For the sake of completeness, the power rates of the χ2 model test for a significance level of 5% are also reported. The results of the simulation are shown in Table 1.

Although the models are severely misspecified under both conditions, the correct rejection rates of the GoF are disappointingly low, in particular those of the RMSEA and SRMR. Please note how close the mean values of these GoF indices are to their suggested cutoff-values for wellfitting models. Referring to our example given in the section “Anything Wrong With Model Fit?”, applied researchers would then too often claim that the items of the newly developed scale were unidimensional although the true structure is clearly two-dimensional. The point of this small and exemplary simulation was to illustrate that the suggested cutoff-values by Hu and Bentler (1999) cannot be generalized to all sorts of different SEMs and hypothesized latent structures.
What Simulation Studies on Model Fit Know That We Don’t Know
Let us step back and briefly summarize what we know from published simulation studies concerning the performance of the GoF and their suggested cutoff-values to detect misspecifications:
- •Sensitivity to detect misspecifications depends on the size of the covariance matrix: More items per factor tend to decrease the RMSEA regardless of the type of misspecification, whereas the CFI tends to worsen, although not always (Breivik & Olsson, 2001; Kenny & McCoach, 2003);
- •Sensitivity to detect misspecifications depends on factor loading size: Small factor loadings (i.e., loadings near .40) decrease correct rejection rates and the power of the χ2 model test (Hancock & Mueller, 2011; Heene et al., 2011; McNeish et al., 2017). Thus, poorer measurement quality results in seemingly well-fitting models;
- •Sensitivity to detect misspecifications partly depends on the type of misspecification (e.g., Chen et al., 2008);
- •Sensitivity to detect misspecifications depends on model types (Fan & Sivo, 2007);
- •Violations of multivariate normality affect the sensitivity of the fit indices and the χ2 model test to detect misspecifications (e.g., Hu & Bentler, 1999).
The bottom line of these findings is: there are no golden rules for cutoff-values, there are only misleading ones. Moreover, inmost of the simulation studies thatwent beyond the models Hu and Bentler (1999) used in their study, their suggested cutoff-values show a poor performance to detect misspecifications raising also questions about the validity of published SEMs having used these cutoff-values.
The Disconnect Between Methodological Research and Standard Practice
The crucial question for EJPA (and other journals) is where the cause of this apparent mismatch between methodological knowledge and actual practice lies and how it can be resolved. McNeish et al. (2017) argue that the high level of technical detail involved in simulation studies inhibits their widespread perception and Marsh, Hau, and Wen (2004) highlight that the lack of clear and applicable guidelines (“no golden fleece”) makes it difficult for researchers who use SEM as an everyday tool for investigating contentrelated questions to integrate these findings into their practice.
To some extent, GoF indices and their cutoff-values will remain ambiguous. It is an undisputable fact that they are (heavily) influenced by circumstantial variables unrelated to model fit. Nobody – and this editorial for the very least – can make the world of GoF easier as it is, and yet, there are some guidelines that at least can bring some light into the dark. This editorial is driven in the spirit and the hope that it helps researchers to find a more adequate way of reporting and evaluating model fit and in particular so when they submit their article to the European Journal of Psychological Assessment.
The World of Model Fit Just Ain’t Simple – and Some Practical Recommendations
Some have suggested that, as an alternative, the χ2 should only be used. However, the χ2 test suffers from similar problems: Its power to detect misspecifications depends on sample size and size of the factor loadings (e.g., Hancock & Mueller, 2011; Heene et al., 2011; McNeish et al., 2017). It is nevertheless in general more statistically powerful than the suggested cutoff-values as many of the cited simulation studies have shown.
Its use, however, is often discouraged in applied papers using a false logic: it is true that with large sample sizes, even small discrepancies between the model-implied and observed covariance matrix will result in a significant test statistic, yet the reverse does not necessarily hold: a significant χ2 test based on a large sample does not imply small discrepancies but could point to large discrepancies. We therefore agree with Ropovik (2015) that, in case of a significant χ2 test, “…it should not be concluded the model approximates the data and ascribe the model test failure to statistical power without a careful inspection of local fit.”
What is therefore needed besides the assessment of global model fit is an inspection of local misspecifications (e.g., missing paths, correlations), regardless of how impressive the GoF indices of a particular study might be. Saris et al. (2009) developed a misspecification detection method based on the expected parameter change in combination with the modification index (MI) and the a priori power of the MI test. Oberski (2010) provides free software to run a misspecification search, which is also implemented in the R package “semTools” (Contributors, 2016). In addition to this, Ropovik (2015) provides a detailed nontechnical overview of various misspecification methods.
Admittedly, the suggested methods mostly apply to misspecifications concerning missing paths, factor correlations, error correlations, or cross loadings.
“The case of assessing violations of unidimensionality is harder to tackle and we cannot provide a definite answer here. Nevertheless, given that GoF showed a poor performance in testing unidimensionality (see also Garrido et al., 2016), it might be advisable to first determine the number of factors using recent methods like bi-cross validation (Owen & Wang, 2015) or parallel analysis (Garrido, Abad, & Ponsoda, 2013).”
We furthermore encourage authors to proactively tackle the issue of model fit by running analyses on local misspecification or by critically discussing cutoff-values of GoF and by making reference to published simulation studies.
References
(2001, March 2).
Adding variables to improve fit: The effect of model size on fit assessment in LISREL . In R. CudeckS. Du ToitD. SörbomEds., Structural equation modeling: Present and future. A Festschrift in honour of Karl Jöreskog (pp. 169–194). Chicago, IL: Scientific Software International.(2008). An empirical evaluation of the use of fixed cutoff points in RMSEA test statistic in structural equation models. Sociological Methods & Research, 36, 462–494. https://doi.org/10.1177/0049124108314720
. (2016). semTools: Useful tools for structural equation modeling, Retrieved from CRAN.R-project.org/package=semTools
(2007). Sensitivity of fit indices to model misspecification and model types. Multivariate Behavioral Research, 42, 509–529. https://doi.org/10.1080/00273170701382864
(2013). A new look at Horn’s parallel analysis with ordinal variables. Psychological Methods, 18, 454–474. https://doi.org/10.1037/a0030005
(2016). Are fit indices really fit to estimate the number of factors with categorical variables? Some cautionary findings via Monte Carlo simulation. Psychological Methods, 21, 93. https://doi.org/10.1037/met0000064
(2011). The reliability paradox in assessing structural relations within covariance structure models. Educational and Psychological Measurement, 71, 306–324. https://doi.org/10.1177/0013164410384856
(2011). Masking misfit in confirmatory factor analysis by increasing unique variances: A cautionary note on the usefulness of cutoff values of fit indices. Psychological Methods, 16, 319–336. https://doi.org/10.1037/a0024917
(2012). Sensitivity of SEM fit indexes with respect to violations of uncorrelated errors. Structural Equation Modeling, 19, 36–50. https://doi.org/10.1080/10705511.2012.634710
(1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling, 6, 1–55. https://doi.org/10.1080/10705519909540118
(2009). Reporting practices in confirmatory factor analysis: An overview and some recommendations. Psychological Methods, 14, 6–23. https://doi.org/10.1037/a0014694
(2003). Effect of the number of variables on measures of fit in structural equation modeling. Structural Equation Modeling, 10, 333–351. https://doi.org/10.1207/S15328007SEM1003_1
(2015). Principles and practice of structural equation modeling. New York, NY: Guilford Publications.
(2004). In search of golden rules: Comment on hypothesis-testing approaches to setting cutoff values for fit indexes and dangers in overgeneralizing Hu and Bentler’s (1999) findings. Structural Equation Modeling, 11, 320–341. https://doi.org/10.1207/s15328007sem1103_2
(2004). A contemplated revision of the NEO Five-Factor Inventory. Personality and Individual Differences, 36, 587–596. https://doi.org/10.1016/s0191-8869(03)00118-1
(2017). The thorny relation between measurement quality and fit index cutoffs in latent variable models. Journal of Personality Assessment, 1–10. https://doi.org/10.1080/00223891.2017.1281286
(2009). Linear causal modeling with structural equations. London, UK: Chapman & Hall.
(2010). Jrule for Mplus, Retrieved from wiki.github.com/daob/JruleMplus/
(2015). Bi-cross-validation for factor analysis. ArXiv:1503.03515 [Stat]. Retrieved from http://arxiv.org/abs/1503.03515
(2015). simsem: SIMulated Structural Equation Modeling, Retrieved from CRAN.R-project.org/package=simsem
(2015). A cautionary note on testing latent variable models. Frontiers in Psychology, 6. https://doi.org/10.3389/fpsyg.2015.01715
(2009). Testing structural equation models or detection of misspecifications. Structural Equation Modeling, 16, 561–582. https://doi.org/10.1080/10705510903203433
(2006). Use of structural equation modeling in operations management research: Looking back and forward. Journal of Operations Management, 24, 148–169.
(2005). Fit indices versus test statistics. Multivariate Behavioral Research, 40, 115–148. https://doi.org/10.1207/s15327906mbr4001_5

