

Measuring Reading Progress in Second Grade
Psychometric Properties of the quop-L2 Test Series
Abstract
Abstract. Learning progress assessments (LPA) are increasingly used by teachers to inform instructional decisions. This study presents evidence for the reliability, validity, and measurement invariance of a newly developed LPA for reading in Grade 2 (quop-L2 – quop Lesetest für zweite Klassen) that assesses the development of reading comprehension in German at the word, sentence, and text levels based on short, equivalent computer-based tests at three-week intervals. All tests were sufficiently reliable. The proposed three-dimensional structure was confirmed by confirmatory factor analysis based on data from N = 1,913 second-grade students. In a subsample of n = 354 students, correlations between quop-L2 and a standardized reading test, teacher judgments, measures of intelligence, and mathematics provided evidence for quop-L2’s convergent and discriminant validity. The equivalent tests were strictly invariant over time. Most importantly, results of structural equation models showed that progress in the quop-L2 assessment at the sentence and text levels was related to growth in standardized reading tests assessed at the beginning and end of the school year. Thus, results indicate that quop-L2 can reliably and validly assess students’ actual reading performance and progress.

The ability to read and understand written text is among the most important skills acquired in school. Students, however, not only start school with different reading-related abilities but also differ in their response to instruction and reading progress (Pfost et al., 2014). To adapt instruction to students’ current needs and abilities, teachers need constant information about their students’ performance and development.
The idea of using data in addition to personal judgments to inform instructional decisions in schools is increasingly discussed in the educational psychological literature. Based on the theoretical frameworks of formative assessment (e.g., Black & Wiliam, 1998) and data-based decision-making (Mandinach, 2012), repeated measures of student performance that provide information about learning progress are particularly helpful. Teachers who monitor their students’ progress on a regular basis were found to affect higher learning in their students compared to teachers who used a single standardized assessment at the beginning of the year (e.g., Förster & Souvignier, 2014, 2015). If teachers know both students’ current achievement levels and their growth over time (i.e., their response to the given instruction), they can adjust instruction to individual needs and make modifications if the instruction does not lead to the desired growth.
Assessment of Learning Progress
To be used for progress monitoring and inform instructional decision-making, an assessment must fulfill specific requirements (Francis et al., 2008). First, for an assessment to inform timely instructional adjustments, it must be applied regularly and frequently (e.g., bi-weekly); thus, it needs to be brief and easy to administer. Moreover, to be reliably interpreted and be a valid measure of learning progress, repeated assessments must be unbiased (i.e., unaffected by practice or form effects) and provide scores on a constant metric. Finally, the assessment must be valid for its actual purpose (Messick, 1989). Consequently, progress assessments are valid for instructional decision-making if they inform about the actual performance level on a single test and the rate of progress across several tests.
Measures typically used in the United States to monitor students’ reading progress are oral reading fluency, which is operationalized as words read correctly per minute (WCPM), and the maze task (Wayman et al., 2007). Both measures are limited in at least two ways. First, they both rely on the assumption that the passages used as reading probes are equally difficult, which, however, must not be the case (Ardoin et al., 2005; Christ & Ardoin, 2009; Good & Kaminski, 2002). And second, both measures only provide a robust indicator of overall reading proficiency but no differentiated information about the efficiency of distinct processes of reading comprehension. Given that reading instruction differs depending on whether reading skills are promoted at the word, sentence, or text level (Walpole & McKenna, 2007), differentiated assessment information about component processes of reading comprehension might be especially useful for informing instructional decisions. Another disadvantage – at least for the oral reading fluency measure – is that it cannot be assessed with the computer, making it very inefficient for teachers in general education who want to monitor the progress of all children in the class.
A differentiated and computer-compatible assessment of component processes of reading comprehension at the word, sentence, and text levels is realized in common standardized reading tests (e.g., Lenhard et al., 2017; Richter et al., 2012). These tests, however, do not meet the requirements for progress monitoring because the single tests take too long, and they have too few equivalent test forms to be used frequently to measure progress.
Reading Progress Assessment quop-L2
The quop-L2 reading progress assessment was developed to close this gap. Our aim was to design a test series consisting of four short, equivalent reading tests that can be used by second-grade teachers in general education as an efficient computer-based assessment to monitor their students’ reading progress at the word, sentence, and text levels. Following the standardized computer-based reading test for primary school children in Germany (ProDi-L; Richter et al., 2012), three tasks were selected to assess word, sentence, and text reading efficiency. For each task, 3-item properties were selected that are hypothesized to influence the item difficulty (Förster & Kuhn, 2021). Each item feature was dichotomously coded (0/1 = lower/higher difficulty). By systematically varying these item properties within each test but keeping them constant across the four tests, we aimed to obtain four equally difficult tests that would be invariant across time and allow inferences about student learning.
At the word level, a word/pseudoword discrimination task is used to assess students’ proficiency in orthographic comparison processes; here, students must decide whether a presented word is a real German word or not. Besides right/wrong, we systematically varied the number of syllables, the word frequency, and the number of orthographic neighbors to manipulate item difficulty. We designed pseudowords by changing the first letter or the first syllable of a word that met the requirements of the item design matrix (e.g., Haum instead of Baum/tree). To assess students’ efficiency in integrating semantic information at the sentence level, a sentence verification task is used. Students must decide whether a sentence (e.g., Ice is hot) makes sense. In the sentences, we manipulated propositional density, content (i.e., strengths of the associations between target words), and complexity of the sentence structure. At the text level, students’ ability to build local coherence and connect information across sentences is assessed by asking students to decide whether a third sentence fits the story made up by the two prior sentences. Here, item features are the use of personal pronouns, content, and coherence/inference (i.e., presence of causal relationships, e.g., therefore, nonetheless).
For each of the four equivalent tests, we developed 20-word items and 13 sentence and text items each. In quop-L2, for every item, both response accuracy and response time are recorded, allowing one to model the efficiency of component processes of reading at the word, sentence, and text levels as a function of response accuracy and response time.
The Present Study
The objective of this study was to evaluate the psychometric properties of the quop-L2 assessment as a measure of students’ reading progress in second grade. Based on data of N = 1,913 students, we first analyzed its reliability, followed by its factorial validity. In accordance with the findings found for ProDi-L, which showed that reading at the word, sentence, and text levels represents three interrelated but separable component processes of reading comprehension (Richter et al., 2012), we predict that a three-dimensional model would fit the data significantly better than a unidimensional model.
Using a subsample of n = 354 students, we further evaluated quop-L2’s convergent and discriminant validity based on correlations with standardized reading tests, teacher judgments, and measures of intelligence and mathematics. We expected to find strong (r > .50) positive correlations between the three quop-L2 scales and standardized reading tests. Likewise, given that teacher judgments show, on average, strong positive correlations with student achievement (Südkamp et al., 2012), we expected high correlations (r > .50) between quop-L2 and teacher judgments of their students’ reading performance. Regarding discriminant validity, we expected correlations between quop-L2 and measures of intelligence and mathematics to be low to moderate and significantly lower compared to the relations between quop-L2 and the convergent and criterial measures.
To draw meaningful conclusions about true change, the different tests need to show strong measurement invariance over time. Given the strict design principles on which each item is based, we predict the measurement invariance of quop-L2 to be strong at least.
Finally, we analyzed whether progress in quop-L2 was indeed related to progress in a standardized reading assessment across one school year. This question, namely whether such growth measurements are really valid, addresses the core assumption of progress monitoring (Schatschneider et al., 2008). Despite its importance, this assumption has rarely been investigated, and the few available studies reported ambiguous findings (Speece & Ritchey, 2005; Tichá et al., 2009; Yeo et al., 2012). We, nevertheless, expected that the growth across one school year assessed with quop-L2 would correlate positively with the growth across the year assessed by a standardized reading test conducted at the beginning and end of the year.
Materials and Method
Participants and Design
The total sample consisted of N = 1,989 students who registered to complete the quop-L2 tests during the 2015–2016 school year. We excluded data from students who had missed all tests (N = 72) and students who were older than 12 years (N = 4). This resulted in a sample of N = 1,913 second-grade students (47.76% female, Mage = 7.90, SDage = 0.48) from six federal states, mostly from Hesse (55.32%) and North Rhine-Westphalia (31.92%). All students completed the quop-L2 reading progress assessment twice (i.e., eight assessments total; intervals were 3 weeks) during the 2015–2016 school year. To prevent confounding of item and time of measurement, the total sample was divided into eight groups, where each group completed a different combination of test halves per time point (Klein Entink et al., 2009). Over the first four-time points, each group completed each item once; for the last four time points, the same four tests were repeated.
In a subsample (n = 354 students), standardized measures of reading, intelligence, and mathematics were applied at the beginning of the school year before the quop-L2 assessments, and teachers were asked to judge their students’ reading performance. Reading comprehension was measured a second time at the end of the school year with the same test used at the beginning of the year. We provide detailed information about the sample in the Supplemental Material (SM 3) at https://osf.io/9vjmt/.
Standardized measures at the beginning and end of the school year were administered as group tests in the schools in paper-pencil format by trained university student assistants. During these measurements, teachers judged students’ reading skills. The quop-L2 reading progress assessments were provided in the quop system developed at the University of Münster (Souvignier et al., 2021). Over the school year, eight equivalent tests (average duration ~7 min each) were completed during self-study periods or in group sessions.
Validation Measures
Reading comprehension was assessed using the standardized reading achievement test for first- to seventh-graders ELFE II (Ein Leseverständnistest für Erst- bis Siebtklässler; Lenhard et al., 2017). In ELFE II, reading comprehension is assessed at the word, sentence, and text levels in a speed test. At the word level, students must choose one of four words that best describes a picture. At the sentence level, students must identify the correct word (out of five choices) to be placed in a sentence. At the text level, short texts consisting of two to four sentences are presented, and students must answer a question about the text by selecting one of four options. Odd-even split-half reliability is convincing (r > .89) for all levels. The ELFE II correlates highly with a standardized reading test (r = .77) and moderately with an intelligence test (r = .39).
Teacher judgments were collected as a second convergent validity measure. Teachers judged their students’ reading skills at the word, sentence, and text levels in a dimensional and a criterial way. For dimensional judgments, teachers rated their students’ reading skills per level on a 7-point Likert scale ranging from far below average to far above average. For the criterial judgment, they estimated how many words, sentences, and text items their students would correctly solve within two minutes. Rating sheets provided information about the average number of words, sentence, and text items that students solved in a pre-study. Thus, criterial teacher judgments can be considered as being informed.
Intelligence was assessed using the language-free culture fair test (CFT 1-R; Weiß & Osterland, 2012) for first- to third-graders. The CFT 1-R has two parts measuring different aspects of general intelligence. Part one assesses perceptual speed; part two assesses basic intellectual skills. Here, we only used the basic intellectual skills assessed using a rule detection task, a classification task, and a matrix task. Retest reliability for the CFT 1-R is very high (r = .94) and correlations with other intelligence measures are also satisfying (r = .63; r = .50).
Mathematical skills were assessed using the standardized achievement test DEMAT 1+ for first-graders (Deutscher Mathematiktest für erste Klassen; Krajewski et al., 2002), which provides norm values for the beginning of second grade. It consists of nine subtests (e.g., addition and subtraction) and is based on a common curriculum for all German federal states. The internal consistency is convincing (r = .88) and the DEMAT 1+ correlates highly with teacher judgments (r = .66) and informal measures of addition and subtraction performance (r = .77).
Analytical Strategy
For all analyses, the open-source software R (version 3.6.3; R Core Team, 2020) was used along with a confidence level of α = .05. Analyses for reliability, factorial validity, and measurement invariance comprised the total sample, while all other analyses used the validation subsample.
To combine the accuracy and response time information of quop-L2, we computed the correct item summed residual time (CISRT) proposed by Van der Maas and Wagenmakers (2005). In the CISRT scoring procedure, response accuracy and response time are simultaneously considered by rewarding a correct response with the remaining time until a time limit; the score for an incorrect response is zero. Thus, correct and fast responses get higher scores than correct but slow responses. Details on the exact calculation procedure, including defined time limits are in the SM 3 (https://osf.io/9vjmt/).
To evaluate reliability, we computed odd-even split-half and retest reliabilities. Moreover, based on the selected invariance model, we estimated quop-L2’s composite reliability (ω1), as well as factor determinacy indices (FDIs), to make sure validity results were meaningful.
Factorial validity was evaluated via confirmatory factor analysis (CFA) for all time points. CFAs were estimated with three parcels with counterbalanced item positions for each level. Covariances between the three latent variables were allowed, as component processes are assumed to interact between levels. Fit indices were compared to those of a model in which covariances between the latent variables were fixed to 1.
Convergent and discriminant validity were evaluated by Pearson correlations between quop-L2 and the validation measures at all time points. Average correlations and their contrasts were implemented as newly defined parameters in lavaan (Rosseel, 2012), which calculates standard errors using the delta-method (Dorfman, 1938). For convergent measures, correlations were computed for word, sentence, and text levels separately, and for discriminant validity, quop-L2 scores were standardized and averaged across levels. Given that teacher judgments are nested within classes, we z-standardized teacher judgments within each class and used these standardized variables in correlational analyses.
We tested measurement invariance across time with sequentially nested models. First, in line with the three-dimensional model, we estimated a longitudinal model with eight points of measurement and nine parcels for each point of measurement (three parcels for each comprehension level) but without modeling any residual inter-parcel covariances. We further estimated a similar model with orthogonal parcel-specific method factors. While the model with method factors yielded a better fit, we observed the phenomenon of factor collapsing (Geiser et al., 2015) and excluded all collapsing factors. For the resulting model with two method factors for sentence parcels, the factorial structure, the factor loadings, the intercepts, and finally, residual variances of indicators were sequentially constrained to be equal to test increasing levels of measurement invariance. We evaluated measurement invariance by ΔCFI and ΔRMSEA, which should be less than .010 and .015 to indicate measurement invariance, respectively (Chen, 2007). Based on the suitable invariance model, we derived factor scores for further analyses of change.
To investigate whether growth in quop-L2 indeed captured reading progress, we used the lavaan package to estimate a linear latent growth model (LGM) with the factor scores from the obtained invariance model (at least strong invariance was required) serving as indicators (Rosseel, 2012). With only two points of measurement available for the standardized reading measure, we modeled the difference between the ELFE II scores from the beginning and end of the school year in a latent change model (LCM) with three parcels with counterbalanced item positions. In the LCM, reading performance at the end of the school year was perfectly predicted by the performance at the beginning of the year and a latent difference variable, which captures change across the year. Hence, the LGM captures growth as average growth between any two successive timepoints, the LCM conceptualizes growth over the period of study. This notable difference between LGM and LCM needs to be kept in mind when interpreting related findings. To validate the quop-L2 assessment as a progress measure, we modeled the LGM and LCM simultaneously and estimated the covariance between the LGM slope and the LCM change as an indicator of validity. The combined model is presented graphically in Figure 1. We report latent mean changes Mδ in standardized units (analogous to Cohen’s d). In addition, we report effect size (ES), which refers to latent mean changes divided by the standard deviation of initial level estimates.
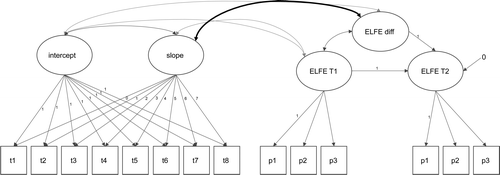
Between 3% and 20% of the data were missing. Logistic regression models indicate that the data follow a missing at random (MAR) pattern (for more details, see the analysis file in the SM, https://osf.io/9vjmt/). Correlational analyses were performed using all pairs of values that were available (all N > 250). In the SEM models, we considered missing values using full information maximum-likelihood (Enders, 2001). All fit indices were evaluated against established cut-offs, that is, RMSEA < .06, SRMR < .08, CFI > .95, TLI > .95 (see West et al., 2012).
Results
Reliability
Descriptive information about all variables, as well as detailed reliability information, is in the SM 4 (https://osf.io/9vjmt/). All odd-even split-half reliabilities exceeded r = .80 at the word and sentence levels and r = .73 at text level, except at T1 (r = .65). Retest reliabilities ranged between .63 and .71. Composite reliabilities based on the measurement invariance model (ω1) ranged between .63 and .76, and FDIs were excellent (all exceeding .87 and all but two exceeding .92). Hence, all but two FDIs clearly surpassed the recommended cut-off in the literature for using factor scores in individual assessments (Ferrando & Lorenzo-Seva, 2018).
Factorial Validity
Three-dimensional CFA models fit significantly better to the data across all measurement points than a CFA model with a fixed covariance of 1, suggesting that quop-L2 offers a differentiated assessment of efficient component processes of reading comprehension at the word, sentence, and text levels. For a relative comparison, the worst fit for the three-dimensional model was (RMSEA = .040, SRMR = .020, CFI = .985, TLI = .977), and the best fit for the fixed-covariance model was (RMSEA = .191, SRMR = .260, CFI = .640, TLI = .520). The fit indices across all models and time points are given in SM 4 (https://osf.io/9vjmt/).
Convergent and Divergent Validity
Correlations between quop-L2 scores and standardized reading measures assessed at the beginning and end of the school year were positive and high at all levels, ranging from .52 to .81 (average r = .63, 95% CI [.60, .67]; see Figure 2). Likewise, moderate to high correlations were found between quop-L2 and teacher judgments (average r = .57, 95% CI [.53, .61]). Similar to correlations with the standardized reading tests, correlations tended to be lower at the text level and earlier measurement points but increased over time, with all r > .50 after the fourth measurement point.
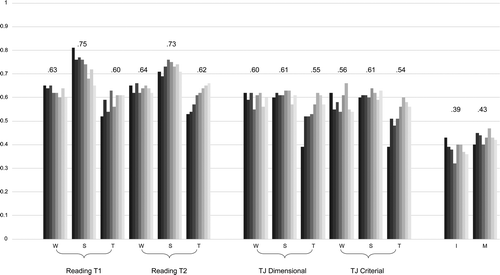
Correlations between total quop-L2 scores and standardized measures of intelligence and mathematics were positive and moderate (average r = .35, 95% CI [.30, .41]), ranging from .32 to .43 and .40 to .47, respectively. Thus, with few exceptions, correlations between quop-L2 and reading measures and reading judgments all exceeded correlations between quop-L2 and measures of intelligence and mathematics. As expected, the average correlations between quop-L2 and convergent and criterial validation measures were significantly higher than the average correlations between quop-L2 and the divergent validation measures (difference of average Fisher-z-transformed correlations: convergent = 0.38, SE = 0.03, p < .001; criterial: = 0.38, SE = 0.03, p < .001).
Measurement Invariance
Strict measurement invariance across time was established for quop-L2. From the configural model with two method factors for sentence parcels to a strict invariance model, CFI decreased only by .002. We found no change in RMSEA and a slight increase in SRMR of .003. The overall fit of this model was good, χ2(2,336) = 4,144.25, p < .001; RMSEA = .027, SRMR = .028, CFI = .944. Based on this strict invariance model, we derived factor scores, which we used in the LGM.
Validity of quop-L2 as a Measure of Reading Progress
The combined LGM and LCM indicated a good fit to the data at the word level (RMSEA = .046, SRMR = .043, CFI = .989, TLI = .988) and an acceptable fit at the sentence and text levels (RMSEA = .077/.068, SRMR = .054/.068, CFI = .971/.965, TLI = .969/.963). Results showed that students’ efficiency in reading comprehension processes significantly increased at all levels across the school year (Mδword = 1.57, SE = 0.24, p < .001, ES = 0.10; Mδsentence = 1.32, SE = 0.19, p < .001, ES = 0.10; Mδtext = 1.38, SE = 0.26, p < .001, ES = 0.15). Likewise, the latent differences in the LCMs between reading skills at the beginning and end of the school year were positive and significantly different from zero (Mδword = 1.58, SE = 0.11, p < .001, ES = 1.07; Mδsentence = 1.73, SE = 0.08, p < .001, ES = 1.01; Mδtext = 1.44, SE = 0.13, p < .001, ES = 1.11). Growth in quop-L2 was significantly related to change in ELFE II at the sentence (r = .37; p < .001) and text levels (r = .37; p = .018) but not at the word level (r = .07; p = .592).
Discussion
This study presents evidence for quop-L2 as a reliable and valid differentiated measure of students’ reading comprehension progress at the word, sentence, and text levels. Our findings demonstrated strict measurement invariance across time, which is critical to draw conclusions about change. Finally, the positive correlations between progress in quop-L2 and change in a standardized reading assessment across one school year at the sentence and text levels indicate that quop-L2 can be used as a measure of reading progress. At the word level, no significant correlation was found.
The proof of quop-L2’s factorial validity represents an important contribution to research on progress monitoring, as reading is mainly assessed by unidimensional, robust indicators like words correct per minute or maze tasks (Wayman et al., 2007). Corresponding with cognitive models, our findings support the assumption that individual differences in the efficiency of orthographic comparison processes, semantic integration, and building of local coherence represent related but psychometrically distinct component processes of reading comprehension (Richter & Christmann, 2009; Richter et al., 2012). quop-L2 might thus provide especially useful information for teachers to adapt reading instruction (Walpole & McKenna, 2007).
Correlations between quop-L2 and reading-related variables support quop-L2’s convergent and discriminant validity. Correlations between quop-L2 and ELFE II were high and are comparable to the correlations found between a combined score of accuracy and response time of Prodi-L and ELFE (Richter et al., 2012). Likewise, the correlations are similar to those found between robust indicators of reading performance commonly used for progress monitoring and standardized reading tests, as reported by several meta-analyses (e.g., Shin & McMaster, 2019). Correlations with two different forms of teacher judgments fluctuate around the average correlation between teacher judgments and student achievement (r = .63) found in a meta-analysis (Südkamp et al., 2012). Correlations between quop-L2 and measures of intelligence and mathematics were significantly lower on average than those between quop-L2 and convergent measures, indicating that quop-L2 measures reading-specific cognitive abilities.
Relating progress in quop-L2 to growth in ELFE II during the school year, positive correlations were found at the sentence and text levels but not at the word level. This missing correlation at the word level is surprising, but it is not unique considering the literature. So far, three studies have investigated the validity of progress measures by comparing different ones (Speece & Ritchey, 2005; Tichá et al., 2009; Yeo et al., 2012), and these studies have found ambiguous results. For example, using bivariate latent growth modeling, Yeo et al. (2012) found that growth in oral reading was not related to growth in maze reading. Thus, our finding complements prior research and highlights the importance of proving the validity of a measure that is to be used to assess learning progress by examining its ability to capture student growth in a meaningful way using longitudinal designs.
One explanation for the missing correlation at the word level could be that the alignment between quop-L2 and ELFE II was lower at the word level than at the sentence and text levels (e.g., Tolar et al., 2014). While ELFE II items at all levels include frequent words, this was only true for quop-L2 at the sentence and text scales. In contrast, item difficulty at the word scale was explicitly manipulated using infrequent words (see Förster & Kuhn, 2021); however, for infrequent words, students’ word identification skills might not improve substantially within one school year. While the orthographic comparison is viewed as especially important for recognizing frequent words (Andrews, 1982), using infrequent words might be better for assessing phonological recoding, a different component process at the word level (Richter et al., 2012).
Limitations and Future Directions
Results are based on the CISRT score. Future studies should clarify what integration of accuracy and response time is theoretically and empirically the most convincing to model reading comprehension as punishing or non-punishing scoring rules are discussed in the literature (e.g., Van der Maas & Wagenmakers, 2005). Furthermore, measures of intelligence and mathematics were only applied at the beginning but not at the end of the school year. Thus, the current design does not allow to disentangle if quop-L2 or ELFE II correctly captures reading progress and whether this progress is specific for reading or is an overall development. Future research should also estimate whether growth over time in quop-L2 provides unique information (e.g., to predict later reading difficulties; Kuhn et al., 2019) beyond what could be predicted by prior reading achievement and overall reading level (Schatschneider et al., 2008). Moreover, the measure was designed and tested in second grade but might also capture reading progress in third or fourth grade. Finally, although the results of the LGM show that quop-L2 assesses learning growth across the school year, further studies should analyze whether quop-L2 is globally and differentially sensitive to instruction even at short intervals of time (Naumann et al., 2014).
Conclusion
quop-L2 can be used as a reliable and valid measure to assess the efficiency of component processes of reading comprehension at the word, sentence, and text levels in second grade. In this respect, it fulfills its intended purpose, namely the psychometrically sound monitoring of student progress in reading.
We thank Jasmin S. J. Munske for help with data collection, preparation, and documentation, Julia Schindler and Tobias Richter for assistance with the selection of item features, Eduardo Cascallar for help with the testing design, the hfp team for support with quop, and Elmar Souvignier and Nina Zeuch for valuable comments throughout the work.
References
(1982). Phonological recoding: Is the regularity effect consistent? Memory & Cognition, 10(6), 565–575. https://doi.org/10.3758/BF03202439
(2005). Accuracy of readability estimates’ predictions of CBM performance. School Psychology Quarterly, 20(1), 1–22. https://doi.org/10.1521/scpq.20.1.1.64193
(1998). Assessment and classroom learning. Assessment in Education: Principles, Policy & Practice, 5(1), 7–74. https://doi.org/10.1080/0969595980050102
(2007). Sensitivity of goodness of fit indexes to lack of measurement invariance. Structural Equation Modeling: A Multidisciplinary Journal, 14(3), 464–504. https://doi.org/10.1080/10705510701301834
(2009). Curriculum-based measurement of oral reading: Passage equivalence and probe-set development. Journal of School Psychology, 47(1), 55–75. https://doi.org/10.1016/j.jsp.2008.09.004
(1938). A note on the delta-method for finding variance formulae. The Biometric Bulletin, 1, 129–137.
(2001). A primer on maximum likelihood algorithms available for use with missing data. Structural Equation Modeling, 8(1), 128–141. https://doi.org/10.1207/s15328007sem0801_7
(2018). Assessing the quality and appropriateness of factor solutions and factor score estimates in exploratory item factor analysis. Educational and Psychological Measurement, 78(5), 762–780. https://doi.org/10.1177/0013164417719308
(2021). Raw data and materials for “Measuring reading progress in second grade: Psychometric properties of the quop-L2 test series”. https://osf.io/9vjmt/
(2021). Ice is hot and water is dry – Developing equivalent reading tests using rule-based item design. European Journal of Psychological Assessment, 37, 1–10. Advance online publication. https://doi.org/10.1027/1015-5759/a000691
(2014). Learning progress assessment and goal setting: Effects on reading achievement, reading motivation and reading self-concept. Learning and Instruction, 32, 91–100. https://doi.org/10.1016/j.learninstruc.2014.02.002
(2015). Effects of providing teachers with information about their students reading progress. School Psychology Review, 44(1), 60–75. https://doi.org/10.17105/SPR44-1.60-75
(2008). Form effects on the estimation of students’ oral reading fluency using DIBELS. Journal of School Psychology, 46(3), 315–342. https://doi.org/10.1016/j.jsp.2007.06.003
(2015). Collapsing factors in multitrait-multimethod models: Examining consequences of a mismatch between measurement design and model. Frontiers in Psychology, 6, Article
946 . https://doi.org/10.3389/fpsyg.2015.00946(2002). DIBELS oral reading fluency passages for first through third grades (Technical Report No. 10). University of Oregon.
(2009). Evaluating cognitive theory: A joint modeling approach using responses and response times. Psychological Methods, 14(1), 54–75. https://doi.org/10.1037/a0014877
(2002). Deutscher Mathematiktest für erste Klassen (DEMAT 1+)
[German mathematic test for first graders] . Hogrefe.(2019). Arithmetische Kompetenz und Rechenschwäche am Ende der Grundschulzeit. Die Rolle statusdiagnostischer und lernverlaufsbezogener Prädiktoren.
[Arithmetic skills and mathematical learning difficulties at the end of elementary school: The role of summative and formative predictors] Empirische Sonderpädagogik, 11(2), 95–117.(2017). ELFE II – Ein Leseverständnistest für Erst- bis Siebtklässler
[ELFE II – A reading comprehension test for first to seventh graders] . Hogrefe.(2012). A perfect time for data use: Using data-driven decision making to inform practice. Educational Psychologist, 47(2), 71–85. https://doi.org/10.1080/00461520.2012.667064
(1989). Meaning and values in test validation: The science and ethics of assessment. Educational Researcher, 18(2), 5–11. https://doi.org/10.3102/0013189X018002005
(2014). Modeling instructional sensitivity using a longitudinal multilevel differential item functioning approach. Journal of Educational Measurement, 51(4), 381–399. https://doi.org/10.1111/jedm.12051
(2014). Individual differences in reading development: A review of 25 years of empirical research on Matthew effects in reading. Review of Educational Research, 84(2), 203–244. https://doi.org/10.3102/0034654313509492
. (2020). R: A language and environment for statistical computing. R Foundation for Statistical Computing. http://www.R-project.org/
(2009).
Lesekompetenz: Prozessebenen und interindividuelle Unterschiede [Reading competence: Process levels and interindividual differences] . In N. GroebenB. HurrelmannEds., Lesekompetenz: Bedingungen, Dimensionen, Funktionen (3rd ed., pp. 25–58). Juventa.(2012). Prozessbezogene Diagnostik von Lesefähigkeiten bei Grundschulkindern
[Process-oriented assessment of reading skills in primary school children] . Zeitschrift für Pädagogische Psychologie, 26(4), 313–331. https://doi.org/10.1024/1010-0652/a000079(2012). lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48(2), 1–36. http://www.jstatsoft.org/v48/i02/
(2008). The importance of measuring growth in response to intervention models: Testing a core assumption. Learning and Individual Differences, 18(3), 308–315. https://doi.org/10.1016/j.lindif.2008.04.005
(2019). Relations between CBM (oral reading and maze) and reading comprehension on state achievement tests: A meta-analysis. Journal of School Psychology, 73, 131–149. https://doi.org/10.1016/j.jsp.2019.03.005
(2021).
quop: An effective web-based approach to monitor student learning progress in reading and mathematics in entire classrooms . In S. JornitzA. WilmersEds., International perspectives on school settings, education policy, and digital strategies. A transatlantic discourse in education research (pp. 291–306). Budrich.(2005). A longitudinal study of the development of oral reading fluency in young children at risk for reading failure. Journal of Learning Disabilities, 38(5), 387–399. https://doi.org/10.1177/00222194050380050201
(2012). Accuracy of teachers’ judgments of students’ academic achievement: A meta-analysis. Journal of Educational Psychology, 104(3), 743–762. https://doi.org/10.1037/a0027627
(2009). Reading progress monitoring for secondary-school students: Reliability, validity, and sensitivity to growth of reading-aloud and maze-selection measures. Learning Disabilities Research & Practice, 24(3), 132–142. https://doi.org/10.1111/j.1540-5826.2009.00287.x
(2014). Predicting reading outcomes with progress monitoring slopes among middle grade students. Learning and Individual Differences, 30, 46–57. https://doi.org/10.1016/j.lindif.2013.11.001
(2005). A psychometric analysis of chess expertise. The American Journal of Psychology, 118(1), 29–60.
(2007). Differentiated reading instruction: Strategies for the primary grades. Guilford Press.
(2007). Literature synthesis on curriculum-based measurement in reading. The Journal of Special Education, 41(2), 85–120. https://doi.org/10.1177/00224669070410020401
(2012). Grundintelligenztest Skala 1 – Revision (CFT 1-R)
[Basic Intelligence Test 1 – Revision] . Hogrefe.(2012).
Model fit and model selection in structural equation modeling . In R. H. HoyleEd., Handbook of structural equation modeling (pp. 209–231). Guilford Press.(2012). Relation between CBM-R and CBM-mR slopes: An application of latent growth modeling. Assessment for Effective Intervention, 37(3), 147–158. https://doi.org/10.1177/1534508411420129


